preface
这篇文章来写一下用 pytorch 训练的一个 CNN 分类器,数据集选用的是 kaggle 上的猫狗大战数据集,只有两个 class ,不过数据集还是挺多的,足够完成我们的分类任务。这份数据集分为 train 和 test 两个文件夹,装着训练集和测试集,还有一个 sample_submission.csv 用来提交我们训练的模型在测试集上的分类情况。值得注意的是,训练集是带标签的,标签在文件名中,如 cat.7741.jpg,而测试集是不带标签的,因为我们模型在测试集中测试后分类的结果是要填到 csv 文件中提交的,所以不能拿测试集来评估模型,我们可以在训练集中划分出一个验证集来评估模型。
划分数据集
首先这是我们需要的所有的模块,缺少的可以用 pip 安装
from torchvision.models.resnet import resnet18
import os
import random
from PIL import Image
import torch.utils.data as data
import numpy as np
import torchvision.transforms as transforms
import torch
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import *
import torchvision.transforms as transforms
import numpy as np
import os
深度学习的背后是依靠着大量标注好的数据集,所以我们要首先将数据集给整好,在 pytorch 中通过继承 torch.utils.data.Dataset 类来实现一个数据集的类,这里我们的训练集和验证集的比例是 7:3
class DogCat(data.Dataset):
def __init__(self, root, transform=None, train=True, val=False):
self.val = val
self.train = train
self.transform = transform
# imgs为一个储存了所有数据集绝对路径的列表
imgs = [os.path.join(root, img) for img in os.listdir(root)]
if self.val:
imgs = sorted(imgs, key=lambda x: int(x.split('.')[-2].split('/')[-1]))
else:
# 根据图片的num排序,如 cat.11.jpg -> 11
imgs = sorted(imgs, key=lambda x: int(x.split('.')[-2]))
imgs_num = len(imgs)
random.shuffle(imgs) # 打乱顺序
if self.train:
self.imgs = imgs[:int(0.7 * imgs_num)]
else:
self.imgs = imgs[int(0.7 * imgs_num):]
# 作为迭代器必须有的方法
def __getitem__(self, index):
img_path = self.imgs[index]
label = 1 if 'dog' in img_path.split('/')[-1] else 0 # 狗的label设为1,猫的设为0
data = Image.open(img_path)
data = self.transform(data)
return data, label
def __len__(self):
return len(self.imgs)
在 torchvision.transforms.Compose 类里有很多针对图像的变化,包括图像旋转以及随即裁剪等增强方式,注意我们这里输入的图片是三维的 PIL image,所以要用 ToTensor() 方法将其转化成 pytorch 的 tensor 形式
# 对数据集训练集的处理,其实可以直接放到 DogCat 类里面去
transform_train = transforms.Compose([
transforms.Resize((256, 256)), # 先调整图片大小至256x256
transforms.RandomCrop((224, 224)), # 再随机裁剪到224x224
transforms.RandomHorizontalFlip(), # 随机的图像水平翻转,通俗讲就是图像的左右对调
transforms.ToTensor(), # Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.2225)) # 归一化,数值是用ImageNet给出的数值
])
# 对数据集验证集的处理
transform_val = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
最后用上面我们定义好的数据集类生成训练集对象和验证集对象,这里我们给了 batch_size 为 20,每 20 个数据进行一次梯度下降,其实一般 batch_size 用 2 的整数次方比较好,num_works 是加载数据用几个线程的意思,在 windows 上要将这个参数去掉,否则会报错
# 生成训练集和验证集
trainset = DogCat('/data/rpcv/kevin/dataset/dogs-vs-cats-redux-kernels-edition/train', transform=transform_train)
valset = DogCat('/data/rpcv/kevin/dataset/dogs-vs-cats-redux-kernels-edition/train', transform=transform_val, train=False, val=True)
# 将训练集和验证集放到 DataLoader 中去,shuffle 进行打乱顺序(在多个 epoch 的情况下)
# num_workers 加载数据用多少的子线程(windows不能用这个参数)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=20, shuffle=True, num_workers=1)
valloader = torch.utils.data.DataLoader(valset, batch_size=20, shuffle=False, num_workers=1)
定义网络
我们直接用 ResNet18 来作为基础结构了,在他的基础上进行迁移学习,因为 ResNet 曾经在 ImageNet 上训练过,并且拿到了第一名的成绩,所以利用它的权重来训练的效果会比较好。定义网络是通过继承 torch.nn.Module 来实现的,这里由于我们是更改 ResNet ,所以在 __init__() 初始化时要传入一个 model 参数。
接着将 ResNet 最后面的一层全连接层去掉改成我们的全连接层,因为 ResNet 在 ImageNet 训练时有 1000 个类,所以它最后全连接输出的是 1000,而我们只要输出 2 就行了。至于 512 是怎么来的呢,全连接上一层的输出是 512,这个可以通过 print(Net) 来看网络的每一层结构,后面会说。
因为我们重写了 forward() 函数,所以要加上 super().__init__() ,而用 x.view(x.size(), -1) 是因为 x 后面接全连接层,这一层的输出是一个 feather-map,要将其所有的特征都变成一个一维向量才能够被全连接层接受,x.size(0) 指的是 batch_size
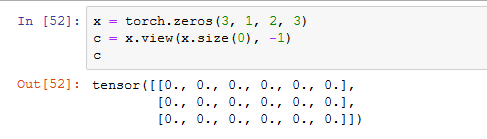
class Net(nn.Module):
def __init__(self, model):
super(Net, self).__init__()
# 去掉model的最后1层
self.resnet_layer = nn.Sequential(*list(model.children())[:-1])
self.Linear_layer = nn.Linear(512, 2) #加上一层参数修改好的全连接层
def forward(self, x):
x = self.resnet_layer(x)
x = x.view(x.size(0), -1)
x = self.Linear_layer(x)
return x
定义训练测试函数
训练函数如下,训练前要将模型调成训练模式 model.train(),然后就初始化 loss 和 精确度,接着将数据集加载进来,这里一次迭代是 batch_size 个数据以及标签,所以 image 的个数是 20,注意每次将样本输入网络前要用 zero_grad() 将梯度清空,否则 loss 会变得很大且无法收敛, loss_function 的传入顺序是 (网络输出,真实标签) ,不能搞反掉,虽然我试了反过来貌似也不会怎样。这里有些函数和变量会在后面定义,慢慢看
def train(epoch):
print('\nEpoch: %d' % epoch)
# scheduler.step()
model.train()
train_acc = 0.0
for batch_idx, (img, label) in enumerate(trainloader): # 迭代器,一次迭代 batch_size 个数据进去
image = img.to(device)
label = label.to(device)
optimizer.zero_grad()
out = model(image)
loss = criterion(out, label)
loss.backward()
optimizer.step()
train_acc = get_acc(out, label)
print("Epoch:%d [%d|%d] loss:%f acc:%f" % (epoch, batch_idx, len(trainloader), loss.mean(), train_acc))
接下来是验证函数,因为没有测试集,我们就在验证集上评估模型的效果,这时我们是不需要更新权重参数的,所以不需要梯度下降,用 torch.no_grad() 取消梯度更新,并且需要用 model.eval() 将模型转入评估模式,不管是在评估还是测试样本,只要不是训练,不需要梯度更新的话就要将 model 转为 eval() 模式。
def val(epoch):
print("\nValidation Epoch: %d" % epoch)
print(len(valloader))
print(len(trainloader))
model.eval()
total = 0
correct = 0
with torch.no_grad():
for batch_idx, (img, label) in enumerate(valloader):
image = img.to(device)
label = label.to(device)
out = model(image)
_, predicted = torch.max(out.data, 1)
total += image.size(0)
correct += predicted.data.eq(label.data).cpu().sum()
print("Epoch:%d [%d|%d] total:%d correct:%d" % (epoch, batch_idx, len(valloader), total, correct.numpy()))
print("Acc: %f " % ((1.0 * correct.numpy()) / total))
统计准确率的话通常就用预测正确的样本数除以总共的样本数,所以经常用到 eq() 函数,它计算两个 size 相同的 tensor 的相等元素的个数,对应位置相等则返回 1 ,不等则返回 0,看下面例子
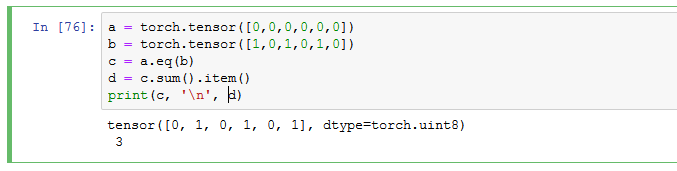
那么训练的时候计算准确率我们定义了一个函数,其实道理是一样的,都是计算预测正确的与总样本的比值,只不过这里换了一个方法,直接用 == 来返回两个 tensor 相等的部分,没有用 eq() ,两种方法都可以。前面说了,output 是个四维的值,第一维代表 batch_size,所以迭代一次的总样本数就是 output.size(0)
def get_acc(output, label):
total = output.shape[0]
_, pred_label = output.max(1)
num_correct = (pred_label == label).sum().item()
return num_correct / total

主函数
函数和网络都定义完了,然后就到主函数交代一些东西,网络用的是预训练好的 ResNet18,优化器用的是 SGD 随机梯度下降,损失函数用的是交叉熵,这个都是超参数,可以随自己喜好修改。在两轮训练之后将模型保存,当然,也可以每一次迭代都保存一次模型,看自己喜欢啦。训练的还挺快的,在两轮之后,验证集上的准确率超过 99%
if __name__ =='__main__':
resnet = resnet18(pretrained=True) # 直接用 resnet 在 ImageNet 上训练好的参数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 若能使用cuda,则使用cuda
model = Net(resnet) # 修改全连接层
# print(model) # 打印出模型结构
model = model.to(device) # 放到 GPU 上跑
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=5e-4) # 设置训练细节
criterion = nn.CrossEntropyLoss() # 分类问题用交叉熵普遍
for epoch in range(2):
train(epoch)
val(epoch)
torch.save(model, 'modelcatdog.pt') # 保存模型
detect.py
跑完一个模型,最刺激的部分当然是用图片测试一下这个模型的准确度了,然后我们新建一个 detect.py 文件和上面的文件放在同一个目录下,我们要将上面定义的网络结构引入进来,否则加载模型后会报错找不到网络,不用头文件的话也行,就要将网络结构的定义复制到这个文件中
import torch
import cv2
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
# from dogcat import Net ##重要,若没有引入这个模型代码,加载模型时会找不到模型
from torchvision import transforms
from PIL import Image
然后我们上面定义了猫是 0,狗是 1,在这里也要对应起来,因为 class 是没有重复的,所以一般用 tuple 来装 class 。接着加载模型,将模型转为 eval() 模式,加载测试的图片,这里我们也要对这张图片进行相应的操作使它的 size 能够被网络接受。
这里我们还将这张图片进行了可视化,输入模型后,如果想知道概率的话还要用 softmax 函数来处理输出数据才能转化成正常的概率。
classes = ('cat', 'dog')
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = torch.load('/data/rpcv/kevin/code/jupyter/modelcatdog.pt') # 加载模型
model = model.to(device)
model.eval() # 把模型转为test模式
img = cv2.imread("/data/rpcv/kevin/dataset/dogs-vs-cats-redux-kernels-edition/test/1.jpg") # 读取要预测的图片
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
trans = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
img = trans(img)
img = img.to(device)
img = img.unsqueeze(0) # 图片扩展多一维,因为输入到保存的模型中是4维的[batch_size,通道,长,宽],而普通图片只有三维,[通道,长,宽]
output = model(img)
prob = F.softmax(output, dim=1) # prob是2个分类的概率
value, predicted = torch.max(prob, 1) # torch.max 返回最大值和最大值的索引号
pred_class = classes[predicted.item()]
print('predicted class is {}, probability is {}%'.format(pred_class, round(value.item(), 6) * 100))

最终输出还是很 OK 的,几乎都有超过 99% 的概率预测正确,文章的代码在我的 GitHub 上可以找到,需要的话大家自取,代码参考修改pytorch提供的resnet接口实现Kaggle猫狗识别,对其错误部分有修改和注释。更多有关 pytorch 的注意事项以及知识点可以看我这篇文章