preface
这篇文章鸽了这么久还是动笔开始写了,YOLO 的论文在这之前一共读了两遍,实际中也有要用到的地方,感觉有些东西还是记一下比较好,免得下次再读的时候给忘了,我写这篇的时候又将这篇论文看了一遍,特此记下一些需要注意的东西
introduction
YOLO(You Only Look Once)是一种目标检测的算法,不像其他的目标检测框架(如 RCNN,DPM 等等),YOLO 将目标检测作为一个回归问题来看待,并且实时性和帧率都比其余的目标检测框架更加优秀。YOLO 可以直接由图像像素得到 bounding box(下面统称 bbox)的坐标和相应类别的概率,YOLO 的结构也很简单, 是个单个卷积神经网络(并不是说整个网络只有一个卷积层),他可以同时预测多个 bbox 并且 bbox 里面的存在的类别的概率。由于 YOLO 是用全图训练的,所以能够直接优化目标检测的表现,因为它可以得到图像区域上下文的信息。
YOLO 也是有些缺点的,主要是对位置的定位不是很精确,尤其是小的物品,原因我们会在下面提到。
principle
YOLO 的主要原理就是将一张图像分成 S x S 个网格,如果一个物体的中心落在这个网格中,那么这个网格就负责检测这个物体。
每个网格预测 B 个 bbox 和 bbox 的置信度,置信度又分为两个部分,一部分是这个网格中多么可能包含物体,另一部分便是预测的物体有多么准确,因此我们置信度表示成$Pr(Object) * IOU^{truth}_{pred}$ ,也就是说,如果一个 bbox 中没有物体的话,置信度就为 0,有的话,$Pr(Object)$ 等于 1, 置信度就等于 IOU(intersection over union) ,IOU 简单来说就是两个矩形交集的面积除以两个矩形并集的面积,值在 [0, 1] 之间,预测效果越好,IOU越大。

每一个 bbox 由 5 个预测值组成,x,y,w,h,置信度。其中,(x,y)是这个 bbox 的中点相对当前网格的坐标,(w,h)是 bbox 相对整张图的宽和高,置信度就是预测的 bbox 和实际标签中的 bbox 的IOU。由于 YOLO 是归一化算法,所以要将 x,y,w,h 都归为 [0, 1] 之间才好,用网上一张图来解释一下是怎么进行归一化的
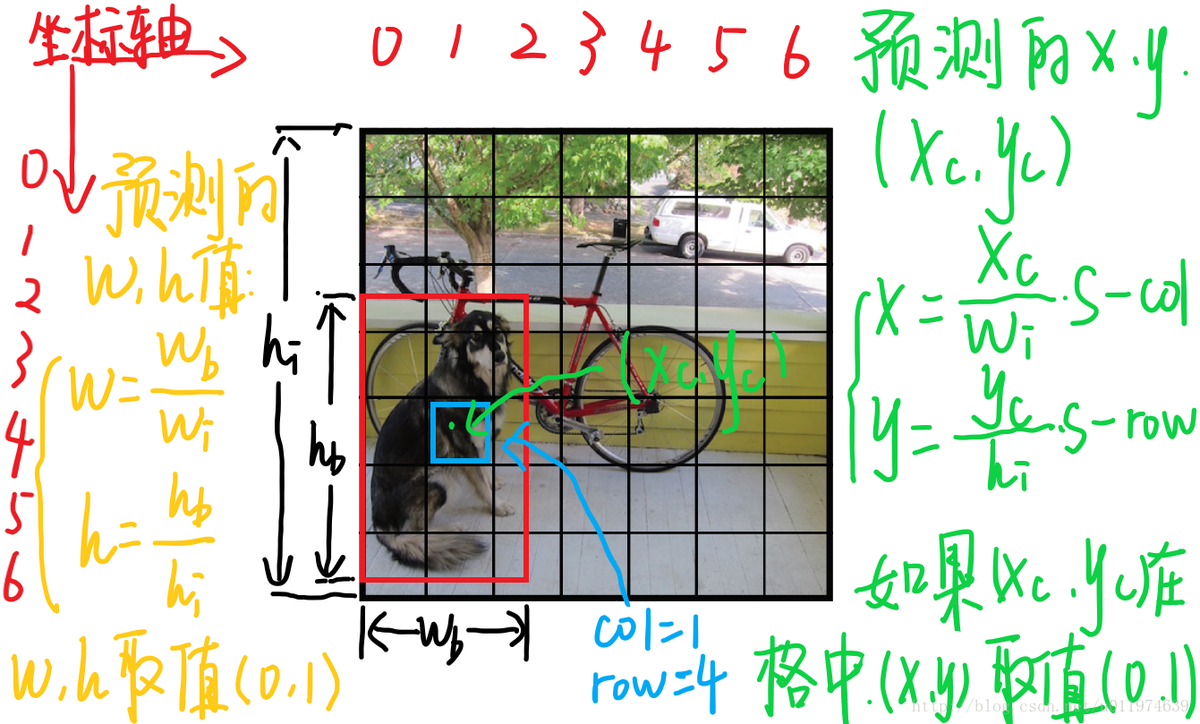
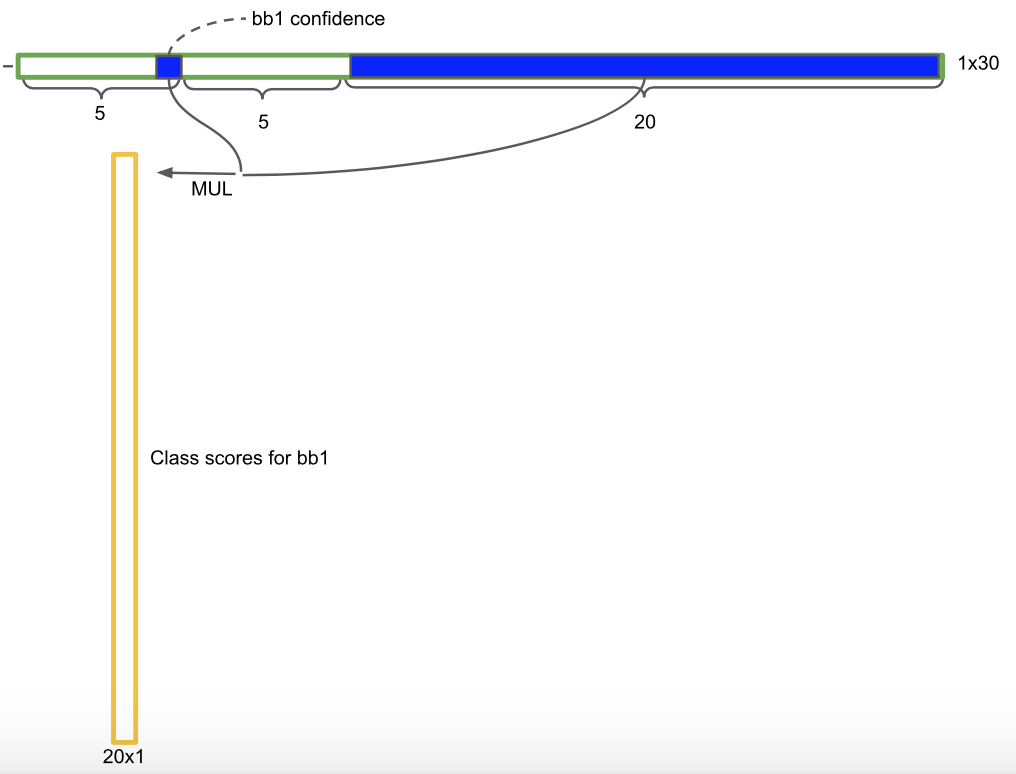
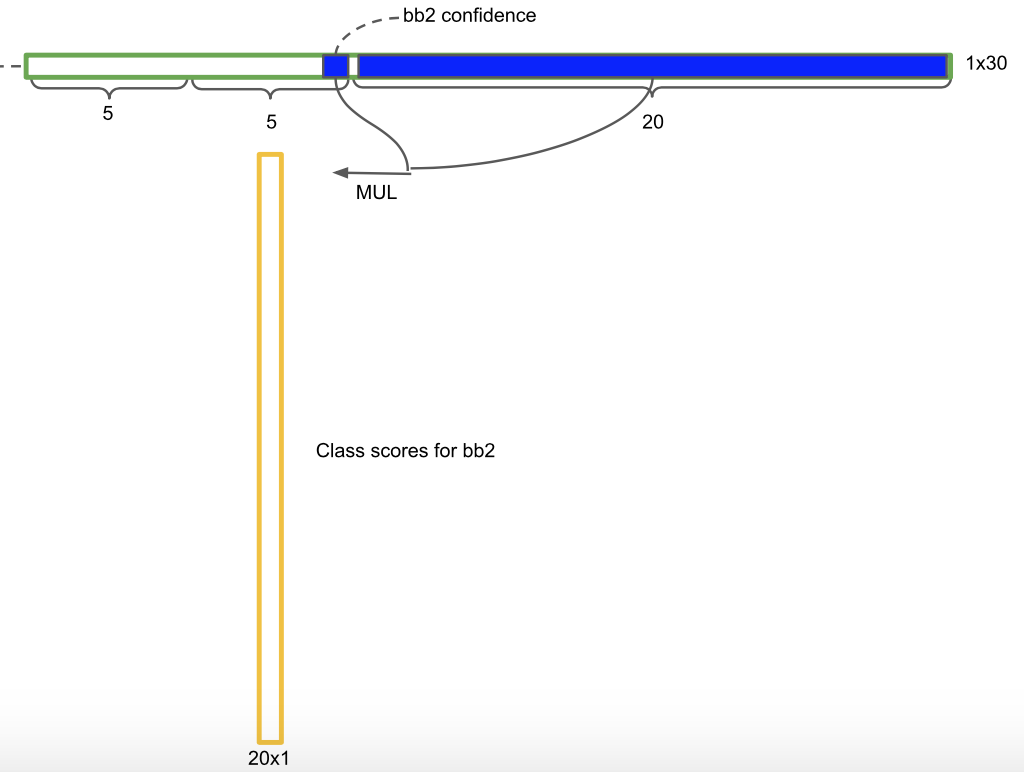
每一个网格也预测 C 个物体属于某个类别的条件概率 $Pr(Class_i|Object)$,并且每一个网格只负责预测一种物体。所以在测试的时候,最终的置信度的计算公式是这样的 \(Pr(Class i | Object) ∗ Pr(Object) ∗ IOU^{truth}_{pred} = Pr(Class i ) ∗ IOU^{truth}_{pred}\)
也就是这个 bbox 中各个类别存在的概率,概率最大的就是预测的结果,用下面这张图可能会理解的更清楚,就是用两个概率相乘
所以网络最终的输出就是 S x S x ( B x 5 + C),作者用的是 VOC 训练集,有 20 个类,B 取 2,因此最终的输出就是个 7 x 7 x 30 的矩阵,如下图所示。
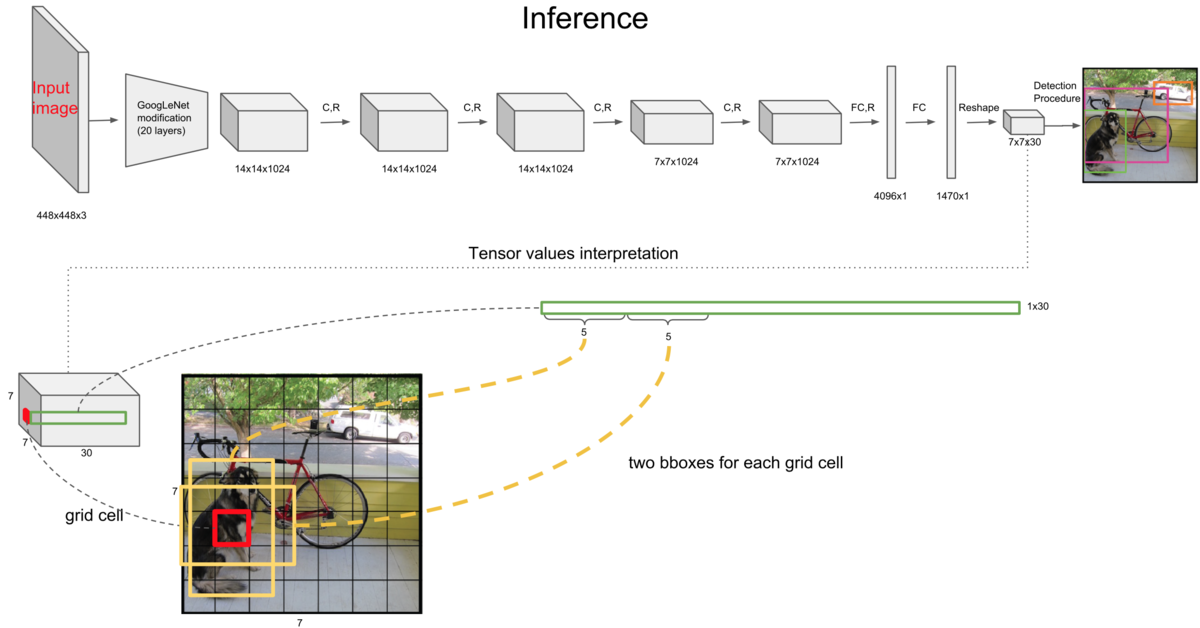
只需要将这 7 x 7 x 30 的矩阵送入 NMS 进行非极大抑制去掉一些 bbox 就可以得到最终的预测结果,NMS 在很多目标检测框架中都有用到,所以这里并没有刻意去提及 NMS,应该是常见的套路了,不用的话最后就会出现一个 Object 周围有很多 bbox,就像下面这样

architecture
下面便是 YOLO 的结构,作者说 YOLO 是参照 GoogLeNet 的灵感,有 24 层卷积层和两层全连接,但是没有用 GoogLeNet 的Inception 模块,只是用了 1 x 1 的卷积核来减少维度信息,还有个 fast YOLO,结构差不多,但是用了更少的卷积层。

training
YOLO 的激活函数在最后一层用的是线性的激活函数,其他层都用的是 Leaky ReLU,损失函数开始用的是简单的残差平方和 sum-squred error,但是这样有几个问题。
首先,这个损失函数将定位误差和分类误差视为相同,另外,一个网格中可能没有物体,这样置信度就为 0,优化的时候很可能梯度跨度太大使模型跑飞,因此加入了两个参数来纠正这个错误,一个 $\lambda_{coord} = 5$ 代表了关于定位的损失参数,$\lambda_{noobj} = 0.5$ 代表了网格中没有物体的损失参数。
另外,对于小的 bbox 和大的 bbox,我们应该要做到同等的误差在大的 bbox 中的影响比在小的 bbox 中的影响小,因此,最后用 w 和 h 的开方来代替直接用 w 和 h进行运算(感觉没什么太大卵用),最终的损失函数如下,分成了几个部分
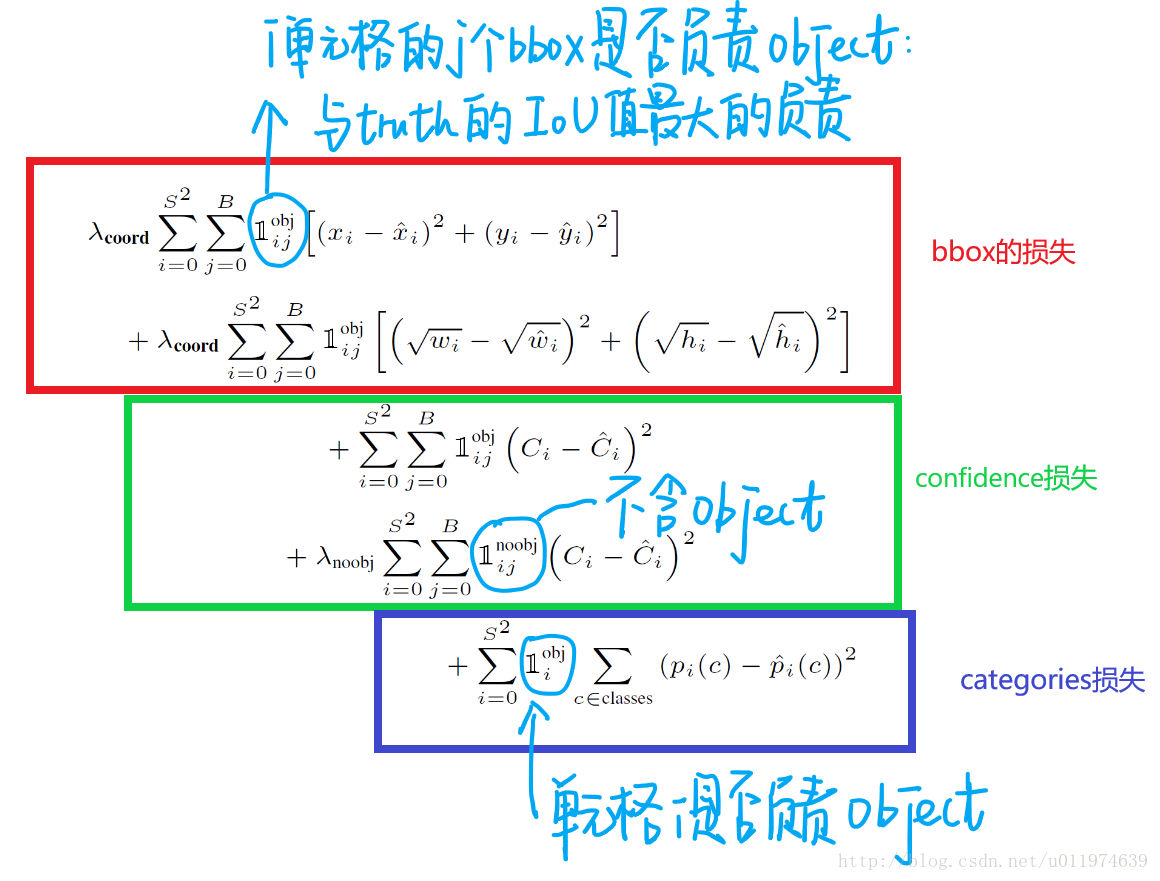
红色框中代表 bbox 的定位误差,也就是 S x S x B 个 bbox 中负责 obj 的 bbox(与标签的 IOU 最大的那个 bbox)的 x,y,w,h 带来的误差。绿色是包含 obj 的 bbox 的置信度损失和不包含的 bbox 的置信度损失,紫色框内是 S x S 个网格中负责某个 obj 的网格预测的类别和标签类别产生的损失。
reference
https://www.jianshu.com/p/13ec2aa50c12 https://zhuanlan.zhihu.com/p/25236464