preface
本文记录 mmdetection 对 PAA 训练的流程,包括标签获取,anchor 生成,前向训练,以及各步骤中 tensor 的形状,仅供复习用处。mmdetection 版本为 2.11.0。
loss 函数
loss 函数这边和上一篇 RetinaNet 不太一样,没有通过 loss_single 函数将 loss 分配到每一个特征图尺度进行计算再累加,而是在图片级别进行单张图片 loss 的计算再累加。因为 PAA 不像 etinaNet 的 anchor 属性都是固定好的,它的 anchor 的属性(正负)是通过网络预测的表现来动态定义的,所以需要将每张图所有的 anchor 都聚在一起方便操作,同时也方便计算每一个 gt_bbox 对应的所有 anchor
@force_fp32(apply_to=('cls_scores', 'bbox_preds', 'iou_preds'))
def loss(self,
cls_scores,
bbox_preds,
iou_preds,
gt_bboxes,
gt_labels,
img_metas,
gt_bboxes_ignore=None):
"""Compute losses of the head.
Args:
cls_scores (list[Tensor]): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W)
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W)
iou_preds (list[Tensor]): iou_preds for each scale
level with shape (N, num_anchors * 1, H, W)
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels (list[Tensor]): class indices corresponding to each box
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes_ignore (list[Tensor] | None): Specify which bounding
boxes can be ignored when are computing the loss.
Returns:
dict[str, Tensor]: A dictionary of loss gmm_assignment.
"""
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
assert len(featmap_sizes) == self.anchor_generator.num_levels
device = cls_scores[0].device
# 这里 get_anchors 部分和 RetinaNet 相同
# 返回两个 List[List[Tensor]]最外面 list 的 size 为 batch_size,里面的是 FPN 特征图的个数,
# 最里面的 tensor 就是每一个特征图中所含有的 anchor 数目,shape 为 (A, 4)
anchor_list, valid_flag_list = self.get_anchors(
featmap_sizes, img_metas, device=device)
label_channels = self.cls_out_channels if self.use_sigmoid_cls else 1
# get_targets 也基本相同,不过在最后没有调用 images_to_levels
cls_reg_targets = self.get_targets(
anchor_list,
valid_flag_list,
gt_bboxes,
img_metas,
gt_bboxes_ignore_list=gt_bboxes_ignore,
gt_labels_list=gt_labels,
label_channels=label_channels,
)
# 这里每一个元素都是一个 len 为 batch_size 的 list,装着每一张图片所有 anchor 匹配目标的信息
(labels, labels_weight, bboxes_target, bboxes_weight, pos_inds,
pos_gt_index) = cls_reg_targets
# 将预测转化成图片级别,返回一个 list,每个元素的 shape:(每一层的[HW]相加, C)
cls_scores = levels_to_images(cls_scores)
cls_scores = [
item.reshape(-1, self.cls_out_channels) for item in cls_scores
]
bbox_preds = levels_to_images(bbox_preds)
bbox_preds = [item.reshape(-1, 4) for item in bbox_preds]
iou_preds = levels_to_images(iou_preds)
iou_preds = [item.reshape(-1, 1) for item in iou_preds]
# 得到了初步筛选出来的正样本的 pos_loss: (cls_loss+reg_loss)
pos_losses_list, = multi_apply(self.get_pos_loss, anchor_list,
cls_scores, bbox_preds, labels,
labels_weight, bboxes_target,
bboxes_weight, pos_inds)
# 根据模型的表现来重新分配一下 anchor 的正负属性
# 注意这里只是根据 cost 大小来分配,只是一个 assign 过程
# 不需要计算梯度,所以用 with torch.no_grad()
with torch.no_grad():
reassign_labels, reassign_label_weight, \
reassign_bbox_weights, num_pos = multi_apply(
self.paa_reassign,
pos_losses_list,
labels,
labels_weight,
bboxes_weight,
pos_inds,
pos_gt_index,
anchor_list)
num_pos = sum(num_pos)
# convert all tensor list to a flatten tensor
# 将所有的东西都 concat 到一起,shape: (Batch_size * num_total_anchors_per_img, C)
cls_scores = torch.cat(cls_scores, 0).view(-1, cls_scores[0].size(-1))
# shape: (Batch_size * num_total_anchors_per_img, 4)
bbox_preds = torch.cat(bbox_preds, 0).view(-1, bbox_preds[0].size(-1))
# shape: (Batch_size * num_total_anchors_per_img, 1)
iou_preds = torch.cat(iou_preds, 0).view(-1, iou_preds[0].size(-1))
# shape: (Batch_size * num_total_anchors_per_img,)
labels = torch.cat(reassign_labels, 0).view(-1)
flatten_anchors = torch.cat(
[torch.cat(item, 0) for item in anchor_list])
labels_weight = torch.cat(reassign_label_weight, 0).view(-1)
bboxes_target = torch.cat(bboxes_target,
0).view(-1, bboxes_target[0].size(-1))
# 计算出 batch 中所有的正样本的 index
pos_inds_flatten = ((labels >= 0)
&
(labels < self.num_classes)).nonzero().reshape(-1)
losses_cls = self.loss_cls(
cls_scores,
labels,
labels_weight,
avg_factor=max(num_pos, len(img_metas))) # avoid num_pos=0
if num_pos:
# 将预测框与对应的 anchor 进行解码得到真实坐标
pos_bbox_pred = self.bbox_coder.decode(
flatten_anchors[pos_inds_flatten],
bbox_preds[pos_inds_flatten])
# 这里由于 PAA 在 assign 的时候选择回归的就是 decoded_box_target
# 所以这里的 bboxes_target 就是 anchor 匹配到的 gt 的真实坐标,不用 decode 了
pos_bbox_target = bboxes_target[pos_inds_flatten]
# 求得正样本 IoU 的真实值
iou_target = bbox_overlaps(
pos_bbox_pred.detach(), pos_bbox_target, is_aligned=True)
losses_iou = self.loss_centerness(
iou_preds[pos_inds_flatten],
iou_target.unsqueeze(-1),
avg_factor=num_pos)
losses_bbox = self.loss_bbox(
pos_bbox_pred,
pos_bbox_target,
iou_target.clamp(min=EPS),
avg_factor=iou_target.sum())
else:
losses_iou = iou_preds.sum() * 0
losses_bbox = bbox_preds.sum() * 0
return dict(
loss_cls=losses_cls, loss_bbox=losses_bbox, loss_iou=losses_iou)
levels_to_images
这个函数将多个 FPN 分支的预测转化成图片级别的,也就是每一张图片中所有的预测,返回一个列表,列表的长度是 batch_size,每一个元素是一个 tensor,包含了这张图片中所有 anchor 的预测值
def levels_to_images(mlvl_tensor):
"""Concat multi-level feature maps by image.
[feature_level0, feature_level1...] -> [feature_image0, feature_image1...]
Convert the shape of each element in mlvl_tensor from (N, C, H, W) to
(N, H*W , C), then split the element to N elements with shape (H*W, C), and
concat elements in same image of all level along first dimension.
Args:
mlvl_tensor (list[torch.Tensor]): list of Tensor which collect from
corresponding level. Each element is of shape (N, C, H, W)
Returns:
list[torch.Tensor]: A list that contains N tensors and each tensor is
of shape (num_elements, C)
"""
batch_size = mlvl_tensor[0].size(0)
batch_list = [[] for _ in range(batch_size)]
channels = mlvl_tensor[0].size(1)
for t in mlvl_tensor:
t = t.permute(0, 2, 3, 1)
t = t.view(batch_size, -1, channels).contiguous()
for img in range(batch_size):
batch_list[img].append(t[img])
return [torch.cat(item, 0) for item in batch_list]
get_targets
注意在 PAA get_targets 里面的 assign 步骤时,由于 PAA 先要将所有的可能的正 anchor 全都找出来 (PAA 目的就是给每一个 anchor 动态分配正负标签,虽然一些模糊的 anchor 的正负属性是需要网络来判断的,但是在背景地方的 anchor 肯定不会是正样本,我们可以先将这部分 anchor 给筛除),所以依然用了 RetinaNet 的 MaxIoUAssigner,但是正样本的阈值非常低,只有 0.1,所以可以认为 IoU 低于 0.1 的都是背景,这点对 PAA 后续的高斯建模很重要。
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.1,
neg_iou_thr=0.1,
min_pos_iou=0,
ignore_iof_thr=-1),
还有个要注意的点是 PAA 默认是 reg_decoded_bbox,所以 bbox_targets 指的是 anchor 匹配到的 gt_bboxes 的真实坐标,而不是他俩之间的偏移量。但是网络预测的依然是偏移量,只是在计算 loss 的时候让预测和 anchor 进行解码,再和 bbox_targets 做 loss,有点绕,只需要记住 PAAHeaD 预测的依然是编码过后的量就行了
if not self.reg_decoded_bbox:
pos_bbox_targets = self.bbox_coder.encode(
sampling_result.pos_bboxes, sampling_result.pos_gt_bboxes)
...
if num_pos:
pos_bbox_pred = self.bbox_coder.decode(
flatten_anchors[pos_inds_flatten],
bbox_preds[pos_inds_flatten])
pos_bbox_target = bboxes_target[pos_inds_flatten]
iou_target = bbox_overlaps(
pos_bbox_pred.detach(), pos_bbox_target, is_aligned=True)
losses_iou = self.loss_centerness(
iou_preds[pos_inds_flatten],
iou_target.unsqueeze(-1),
avg_factor=num_pos)
losses_bbox = self.loss_bbox(
pos_bbox_pred,
pos_bbox_target,
iou_target.clamp(min=EPS),
avg_factor=iou_target.sum())
another important thing is,由于在 get_targets 时,我们的 anchor 已经是筛除了越界的 anchor,所以得到的 index 可能不正确,因此我们要重新计算一下正样本 anchor 在原来的 anchor 集合上的 index
# Due to valid flag of anchors, we have to calculate the real pos_inds
# in origin anchor set.
pos_inds = []
for i, single_labels in enumerate(labels):
pos_mask = (0 <= single_labels) & (
single_labels < self.num_classes)
pos_inds.append(pos_mask.nonzero().view(-1))
get_pos_loss
这个函数以 img_level 的形式,对一张图片中所有的正样本 anchor 进行 loss 计算
def get_pos_loss(self, anchors, cls_score, bbox_pred, label, label_weight,
bbox_target, bbox_weight, pos_inds):
"""Calculate loss of all potential positive samples obtained from first
match process.
Args:
anchors (list[Tensor]): Anchors of each scale.
cls_score (Tensor): Box scores of single image with shape
(num_anchors, num_classes)
bbox_pred (Tensor): Box energies / deltas of single image
with shape (num_anchors, 4)
label (Tensor): classification target of each anchor with
shape (num_anchors,)
label_weight (Tensor): Classification loss weight of each
anchor with shape (num_anchors).
bbox_target (dict): Regression target of each anchor with
shape (num_anchors, 4).
bbox_weight (Tensor): Bbox weight of each anchor with shape
(num_anchors, 4).
pos_inds (Tensor): Index of all positive samples got from
first assign process.
Returns:
Tensor: Losses of all positive samples in single image.
"""
if not len(pos_inds):
return cls_score.new([]),
# 将特征图级别的 anchor concat 在一起,与其他输入 shape 对应
anchors_all_level = torch.cat(anchors, 0)
# 将 MaxIouAssigner 分配的正样本的预测值拿出来
pos_scores = cls_score[pos_inds]
pos_bbox_pred = bbox_pred[pos_inds]
pos_label = label[pos_inds]
pos_label_weight = label_weight[pos_inds]
pos_bbox_target = bbox_target[pos_inds]
pos_bbox_weight = bbox_weight[pos_inds]
pos_anchors = anchors_all_level[pos_inds]
pos_bbox_pred = self.bbox_coder.decode(pos_anchors, pos_bbox_pred)
# to keep loss dimension
# shape: (num_pos_anchors, C)
loss_cls = self.loss_cls(
pos_scores,
pos_label,
pos_label_weight,
avg_factor=self.loss_cls.loss_weight,
reduction_override='none')
# shape: (num_pos_anchors,)
loss_bbox = self.loss_bbox(
pos_bbox_pred,
pos_bbox_target,
pos_bbox_weight,
avg_factor=self.loss_cls.loss_weight,
reduction_override='none')
# shape: (num_pos_anchors,)
loss_cls = loss_cls.sum(-1)
pos_loss = loss_bbox + loss_cls
return pos_loss,
paa_reassign
之前我们已经用了 MaxIouAssigner 来进行了一波粗筛选,把确定是背景的负样本给除去了,然后我们就要根据这些粗的样本的表现来给他们重新分配标签,所以这个函数输入这些粗样本计算出来的 loss 以及这些样本,输出重新 assign 之后这些样本的标签和 index。再次说明,这个函数是针对每一张图来计算的。
def paa_reassign(self, pos_losses, label, label_weight, bbox_weight,
pos_inds, pos_gt_inds, anchors):
"""Fit loss to GMM distribution and separate positive, ignore, negative
samples again with GMM model.
Args:
pos_losses (Tensor): Losses of all positive samples in
single image.
label (Tensor): classification target of each anchor with
shape (num_anchors,)
label_weight (Tensor): Classification loss weight of each
anchor with shape (num_anchors).
bbox_weight (Tensor): Bbox weight of each anchor with shape
(num_anchors, 4).
pos_inds (Tensor): Index of all positive samples got from
first assign process.
pos_gt_inds (Tensor): Gt_index of all positive samples got
from first assign process.
anchors (list[Tensor]): Anchors of each scale.
Returns:
tuple: Usually returns a tuple containing learning targets.
- label (Tensor): classification target of each anchor after
paa assign, with shape (num_anchors,)
- label_weight (Tensor): Classification loss weight of each
anchor after paa assign, with shape (num_anchors).
- bbox_weight (Tensor): Bbox weight of each anchor with shape
(num_anchors, 4).
- num_pos (int): The number of positive samples after paa
assign.
"""
if not len(pos_inds):
return label, label_weight, bbox_weight, 0
label = label.clone()
label_weight = label_weight.clone()
bbox_weight = bbox_weight.clone()
# 这张图中的 gt_box 的数量,14
num_gt = pos_gt_inds.max() + 1
# 这么多个尺度的特征图,5
num_level = len(anchors)
# [16800, 4200, 1050, 273, 77]
num_anchors_each_level = [item.size(0) for item in anchors]
# [0, 16800, 4200, 1050, 273, 77]
num_anchors_each_level.insert(0, 0)
# 一直累加,作为截至某个阶段所有 anchor 数的记录
# array([0, 16800, 21000, 22050, 22323, 22400])
inds_level_interval = np.cumsum(num_anchors_each_level)
pos_level_mask = []
for i in range(num_level):
# pos_inds 里面存储的是所有 FPN 层的粗正样本 index flatten 后的值
# 把每一个特征图阶段的粗正样本给找出来,shape:(num_pos_anchors),方便切割样本
mask = (pos_inds >= inds_level_interval[i]) & (
pos_inds < inds_level_interval[i + 1])
pos_level_mask.append(mask)
pos_inds_after_paa = [label.new_tensor([])]
ignore_inds_after_paa = [label.new_tensor([])]
# 对每一个 gt_box 进行操作
for gt_ind in range(num_gt):
pos_inds_gmm = []
pos_loss_gmm = []
# 与当前这个 gt_box 匹配的所有 anchor 的 index
gt_mask = pos_gt_inds == gt_ind
for level in range(num_level):
level_mask = pos_level_mask[level]
# 找出是该层的粗正样本并且被分配到该 gt_box 的索引
level_gt_mask = level_mask & gt_mask
# pos_losses:shape(num_pos_anchors),self.topk=9
# 这里按照 loss 取出最小的 topk 个元素,也就是最像正样本的
# topk 的样本进入候选正样本,其他的被当作负样本
# 理想情况下一个 gt 在每一层最多能够匹配 9 个样本,也够了
value, topk_inds = pos_losses[level_gt_mask].topk(
min(level_gt_mask.sum(), self.topk), largest=False)
# 此时就找到了该 gt_box 在该 FPN 层的候选样本
pos_inds_gmm.append(pos_inds[level_gt_mask][topk_inds])
pos_loss_gmm.append(value)
# shape: (num_candidate)
pos_inds_gmm = torch.cat(pos_inds_gmm)
pos_loss_gmm = torch.cat(pos_loss_gmm)
# fix gmm need at least two sample
if len(pos_inds_gmm) < 2:
continue
device = pos_inds_gmm.device
# 按照 loss 进行升序排序
pos_loss_gmm, sort_inds = pos_loss_gmm.sort()
pos_inds_gmm = pos_inds_gmm[sort_inds]
pos_loss_gmm = pos_loss_gmm.view(-1, 1).cpu().numpy()
min_loss, max_loss = pos_loss_gmm.min(), pos_loss_gmm.max()
# 开始对每一个 gt_box 的候选样本进行 gmm 建模
means_init = np.array([min_loss, max_loss]).reshape(2, 1)
# 每个样本属于正负样本的概率都是 0.5
weights_init = np.array([0.5, 0.5])
precisions_init = np.array([1.0, 1.0]).reshape(2, 1, 1) # full
if self.covariance_type == 'spherical':
precisions_init = precisions_init.reshape(2)
elif self.covariance_type == 'diag':
precisions_init = precisions_init.reshape(2, 1)
elif self.covariance_type == 'tied':
precisions_init = np.array([[1.0]])
if skm is None:
raise ImportError('Please run "pip install sklearn" '
'to install sklearn first.')
# 直接掉包求解,参数 2 是代表要聚的类别数
gmm = skm.GaussianMixture(
2,
weights_init=weights_init,
means_init=means_init,
precisions_init=precisions_init,
covariance_type=self.covariance_type)
# 调用 fit 函数开始求解
gmm.fit(pos_loss_gmm)
# 得到每一个样本的分配结果
# 0(正样本) 或者 1(负样本),shape: (num_candidate)
gmm_assignment = gmm.predict(pos_loss_gmm)
# 得到每一个样本的分配结果对应的分数, shape: (num_candidate)
scores = gmm.score_samples(pos_loss_gmm)
gmm_assignment = torch.from_numpy(gmm_assignment).to(device)
scores = torch.from_numpy(scores).to(device)
# 将正负样本进行分割,得到了匹配这个 gt_box 的正样本 anchor 的 index
pos_inds_temp, ignore_inds_temp = self.gmm_separation_scheme(
gmm_assignment, scores, pos_inds_gmm)
pos_inds_after_paa.append(pos_inds_temp)
ignore_inds_after_paa.append(ignore_inds_temp)
# 得到了这张图片中的所有正样本的 index
pos_inds_after_paa = torch.cat(pos_inds_after_paa)
# 空的,没有忽略的样本
ignore_inds_after_paa = torch.cat(ignore_inds_after_paa)
# 判断经过 PAA 前后,粗正样本的标签被改成负样本的 index
# shape: (num_pos_anchors, num_pos_anchors_after_paa) -> (num_pos_anchors)
# 实现起来就是用 PAA 筛选后的所有 index 和筛选前的每一个 index 进行判断是否相等
# 只要有一个相等的话就说明这个 anchor 在 PAA 筛选之后还是正样本
reassign_mask = (pos_inds.unsqueeze(1) != pos_inds_after_paa).all(1)
# 由正样本变成负样本的 anchor index
reassign_ids = pos_inds[reassign_mask]
label[reassign_ids] = self.num_classes
label_weight[ignore_inds_after_paa] = 0
bbox_weight[reassign_ids] = 0
num_pos = len(pos_inds_after_paa)
return label, label_weight, bbox_weight, num_pos
gmm_separation_scheme
上面经过 gmm 已经将一个 gt_box 的所有待选正样本进行了建模预测分布,给每个样本都分配了一个标签和分数,这里就将正负样本分离,可以看到论文中的图,这里实现的是 c 方法,也就是说确定一个正样本的概率在峰值出的位置,当样本的 score 大于这个位置的话就是正样本,否则就是负样本,这里没有忽略样本。
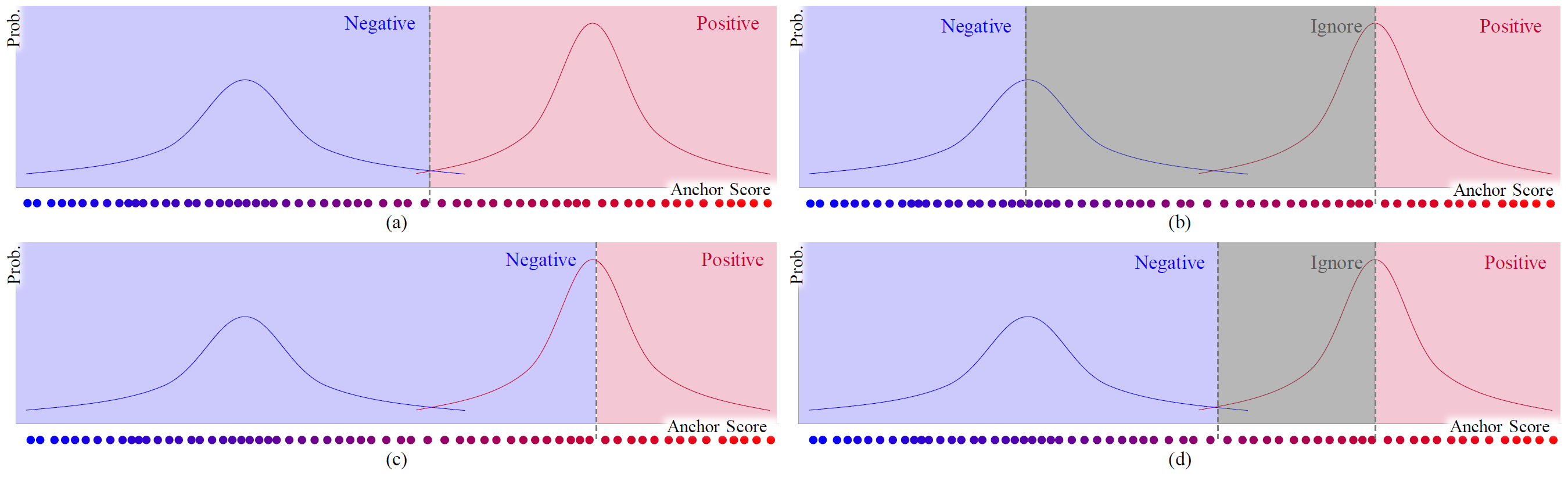
def gmm_separation_scheme(self, gmm_assignment, scores, pos_inds_gmm):
"""A general separation scheme for gmm model.
It separates a GMM distribution of candidate samples into three
parts, 0 1 and uncertain areas, and you can implement other
separation schemes by rewriting this function.
Args:
gmm_assignment (Tensor): The prediction of GMM which is of shape
(num_samples,). The 0/1 value indicates the distribution
that each sample comes from.
scores (Tensor): The probability of sample coming from the
fit GMM distribution. The tensor is of shape (num_samples,).
pos_inds_gmm (Tensor): All the indexes of samples which are used
to fit GMM model. The tensor is of shape (num_samples,)
Returns:
tuple[Tensor]: The indices of positive and ignored samples.
- pos_inds_temp (Tensor): Indices of positive samples.
- ignore_inds_temp (Tensor): Indices of ignore samples.
"""
# The implementation is (c) in Fig.3 in origin paper instead of (b).
# You can refer to issues such as
# https://github.com/kkhoot/PAA/issues/8 and
# https://github.com/kkhoot/PAA/issues/9.
# 找到属于正样本的 index
fgs = gmm_assignment == 0
pos_inds_temp = fgs.new_tensor([], dtype=torch.long)
ignore_inds_temp = fgs.new_tensor([], dtype=torch.long)
if fgs.nonzero().numel():
# 这就是正样本的概率在最大值处的 index,也就是论文中的红线处
# 但是论文中的评估是用 score,我们用的是 loss,所以是反过来的
# 也就是说小于等于这个点的都是正样本
_, pos_thr_ind = scores[fgs].topk(1)
pos_inds_temp = pos_inds_gmm[fgs][:pos_thr_ind + 1]
ignore_inds_temp = pos_inds_gmm.new_tensor([])
return pos_inds_temp, ignore_inds_temp
ATSSHead.get_bboxes
这一部分就是在推理的时候用到的代码了,也就是网络前向传播得到 score 和 bbox prediction 以及 iou 之后如何通过这些信息得到真实的框。这个函数是基于 batch 进行推理的,_get_bboxes 是主要实现的逻辑。PAAHead 中并没有重写 get_bboxes 函数,所以直接继承的 ATSSHead,但是重写了 _get_bboxes 的逻辑。
@force_fp32(apply_to=('cls_scores', 'bbox_preds', 'centernesses'))
def get_bboxes(self,
cls_scores,
bbox_preds,
centernesses,
img_metas,
cfg=None,
rescale=False,
with_nms=True):
"""Transform network output for a batch into bbox predictions.
Args:
cls_scores (list[Tensor]): Box scores for each scale level
with shape (N, num_anchors * num_classes, H, W).
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W).
centernesses (list[Tensor]): Centerness for each scale level with
shape (N, num_anchors * 1, H, W).
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
cfg (mmcv.Config | None): Test / postprocessing configuration,
if None, test_cfg would be used. Default: None.
rescale (bool): If True, return boxes in original image space.
Default: False.
with_nms (bool): If True, do nms before return boxes.
Default: True.
Returns:
list[tuple[Tensor, Tensor]]: Each item in result_list is 2-tuple.
The first item is an (n, 5) tensor, where 5 represent
(tl_x, tl_y, br_x, br_y, score) and the score between 0 and 1.
The shape of the second tensor in the tuple is (n,), and
each element represents the class label of the corresponding
box.
"""
cfg = self.test_cfg if cfg is None else cfg
assert len(cls_scores) == len(bbox_preds)
num_levels = len(cls_scores)
device = cls_scores[0].device
featmap_sizes = [cls_scores[i].shape[-2:] for i in range(num_levels)]
mlvl_anchors = self.anchor_generator.grid_anchors(
featmap_sizes, device=device)
cls_score_list = [cls_scores[i].detach() for i in range(num_levels)]
bbox_pred_list = [bbox_preds[i].detach() for i in range(num_levels)]
centerness_pred_list = [
centernesses[i].detach() for i in range(num_levels)
]
img_shapes = [
img_metas[i]['img_shape'] for i in range(cls_scores[0].shape[0])
]
scale_factors = [
img_metas[i]['scale_factor'] for i in range(cls_scores[0].shape[0])
]
result_list = self._get_bboxes(cls_score_list, bbox_pred_list,
centerness_pred_list, mlvl_anchors,
img_shapes, scale_factors, cfg, rescale,
with_nms)
return result_list
_get_bboxes
def _get_bboxes(self,
cls_scores,
bbox_preds,
iou_preds,
mlvl_anchors,
img_shapes,
scale_factors,
cfg,
rescale=False,
with_nms=True):
"""Transform outputs for a single batch item into labeled boxes.
This method is almost same as `ATSSHead._get_bboxes()`.
We use sqrt(iou_preds * cls_scores) in NMS process instead of just
cls_scores. Besides, score voting is used when `` score_voting``
is set to True.
"""
assert with_nms, 'PAA only supports "with_nms=True" now'
assert len(cls_scores) == len(bbox_preds) == len(mlvl_anchors)
batch_size = cls_scores[0].shape[0]
mlvl_bboxes = []
mlvl_scores = []
mlvl_iou_preds = []
for cls_score, bbox_pred, iou_preds, anchors in zip(
cls_scores, bbox_preds, iou_preds, mlvl_anchors):
assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
# shape: (B,HW,C),用 sigmoid 是因为定义分类损失的时候 use_sigmoid=True
# 否则就用 softmax 进行归一化
scores = cls_score.permute(0, 2, 3, 1).reshape(
batch_size, -1, self.cls_out_channels).sigmoid()
# shape: (B,HW,4)
bbox_pred = bbox_pred.permute(0, 2, 3,
1).reshape(batch_size, -1, 4)
# shape: (B,HW)
iou_preds = iou_preds.permute(0, 2, 3, 1).reshape(batch_size,
-1).sigmoid()
nms_pre = cfg.get('nms_pre', -1)
# 每一层只保留分数最高的 nms_pre 个待选框(PAA 里面是 1000)
if nms_pre > 0 and scores.shape[1] > nms_pre:
# shape: (B,HW),这里找到了对每一个 anchor 预测的分类最高的 score,但是不知道是什么类别
max_scores, _ = (scores * iou_preds[..., None]).sqrt().max(-1)
# topk_inds:shape (B, nms_pre),找到了每一层得分前 nms_pre 个 anchor 的索引
_, topk_inds = max_scores.topk(nms_pre)
batch_inds = torch.arange(batch_size).view(
-1, 1).expand_as(topk_inds).long()
anchors = anchors[topk_inds, :]
bbox_pred = bbox_pred[batch_inds, topk_inds, :]
scores = scores[batch_inds, topk_inds, :]
iou_preds = iou_preds[batch_inds, topk_inds]
else:
anchors = anchors.expand_as(bbox_pred)
# 进行解码得到真实坐标
bboxes = self.bbox_coder.decode(
anchors, bbox_pred, max_shape=img_shapes)
mlvl_bboxes.append(bboxes)
mlvl_scores.append(scores)
mlvl_iou_preds.append(iou_preds)
# shape: (B, HW_in_all_scale, 4)
batch_mlvl_bboxes = torch.cat(mlvl_bboxes, dim=1)
if rescale:
batch_mlvl_bboxes /= batch_mlvl_bboxes.new_tensor(
scale_factors).unsqueeze(1)
# shape: (B, HW_in_all_scale, C)
batch_mlvl_scores = torch.cat(mlvl_scores, dim=1)
# Add a dummy background class to the backend when using sigmoid
# remind that we set FG labels to [0, num_class-1] since mmdet v2.0
# BG cat_id: num_class
# 在 score 维度加上一个背景类别,shape: (B, HW_in_all_scale, 1)
padding = batch_mlvl_scores.new_zeros(batch_size,
batch_mlvl_scores.shape[1], 1)
# 合并两个列表, shape: (B, HW_in_all_scale, C+1)
batch_mlvl_scores = torch.cat([batch_mlvl_scores, padding], dim=-1)
# shape: (B, HW_in_all_scale)
batch_mlvl_iou_preds = torch.cat(mlvl_iou_preds, dim=1)
# shape: (B, HW_in_all_scale, C+1)
batch_mlvl_nms_scores = (batch_mlvl_scores *
batch_mlvl_iou_preds[..., None]).sqrt()
det_results = []
# 对每一张图片进行 nms 操作
for (mlvl_bboxes, mlvl_scores) in zip(batch_mlvl_bboxes,
batch_mlvl_nms_scores):
# 返回最终检测框的坐标以及标签,shape:(n,4), (n)
det_bbox, det_label = multiclass_nms(
mlvl_bboxes,
mlvl_scores,
cfg.score_thr,
cfg.nms,
cfg.max_per_img,
score_factors=None)
if self.with_score_voting and len(det_bbox) > 0:
det_bbox, det_label = self.score_voting(
det_bbox, det_label, mlvl_bboxes, mlvl_scores,
cfg.score_thr)
det_results.append(tuple([det_bbox, det_label]))
# 返回每一张图片对应的结果
return det_results
test_cfg=dict(
# 每一层只保留分数最高的 nms_pre 个待选框
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.6),
# 每张图中最多检测 100 个物体
max_per_img=100)
score_voting
TODO
bbox2result
在 PAAHead 里面得到 bbox 结果之后在 singlg_stage.py 文件中调用 bbox2result 将结果整理,返回每一类的检测结果
def simple_test(self, img, img_metas, rescale=False):
x = self.extract_feat(img)
outs = self.bbox_head(x)
bbox_list = self.bbox_head.get_bboxes(
*outs, img_metas, rescale=rescale)
bbox_results = [
bbox2result(det_bboxes, det_labels, self.bbox_head.num_classes)
for det_bboxes, det_labels in bbox_list
]
return bbox_results
def bbox2result(bboxes, labels, num_classes):
"""Convert detection results to a list of numpy arrays.
Args:
bboxes (torch.Tensor | np.ndarray): shape (n, 5)
labels (torch.Tensor | np.ndarray): shape (n, )
num_classes (int): class number, including background class
Returns:
list(ndarray): bbox results of each class
"""
if bboxes.shape[0] == 0:
return [np.zeros((0, 5), dtype=np.float32) for i in range(num_classes)]
else:
if isinstance(bboxes, torch.Tensor):
bboxes = bboxes.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
# 结果整理,返回每一类的检测结果
return [bboxes[labels == i, :] for i in range(num_classes)]
reference
mmdetection最小复刻版(十一):概率Anchor分配机制PAA深入分析 - 开发者头条 (toutiao.io)