preface
最近有一个需求,表面上是人脸检测,但是需要在没有看到人脸的情况下通过对上半身的检测也能够知道这里有人。从公开的数据集上调研一下可能性,但是没有发现有类似的数据集,于是想着从其他的方式入手,大致方向有三个,第一个就是利用人脸检测的框来推断出身体的位置,从而得到身体的框;第二种就是通过行人检测的数据集,将行人框的高度缩小一半来得到上半身的框;第三种是利用人体关键点检测数据集,利用关键点来确定上半身的框。
经过调研和讨论,还是觉得用关键点的方式比较靠谱,最终选择了 COCO 数据集,它有 17 个关键点标注,我们可以利用左右肩和左右臀这四个关键点来实现上半身的检测,整一个流程的 pipeline 如下图,先用一个矩形框将关键点给包围起来,再用一个 scale 稍微放大一点,就是最终得到的上半身的检测框了。

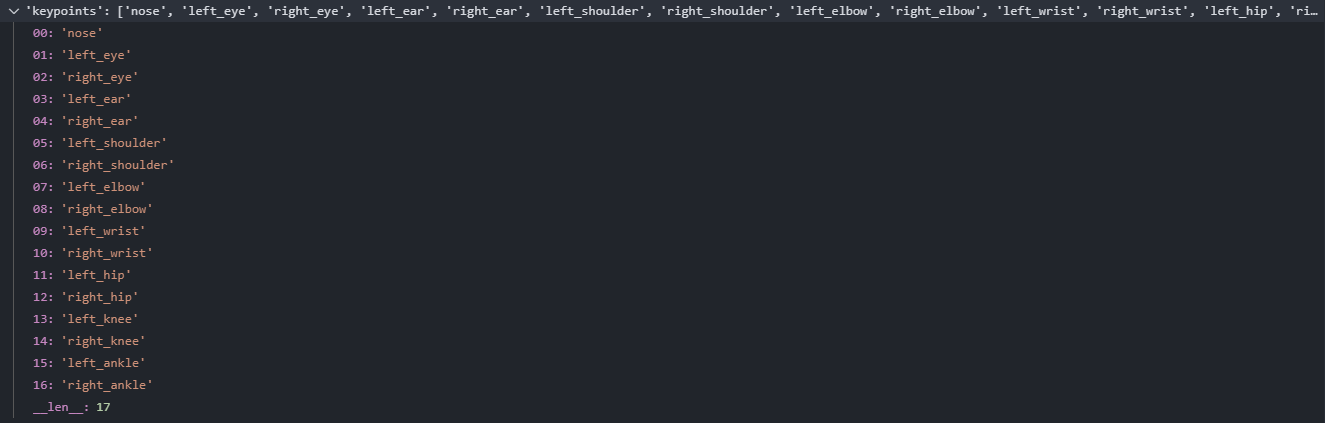
这里是 COCO 对人体标注的所有关键点,我们只需要取其中的四个就行了,注意 COCO 的一个关键点对应着数组中的三个数,也就是 (x, y, flag),其中 flag 为 0 代表关键点没有标注,为 1 代表关键点标注了但是被遮挡了,为 2 代表关键点标注了并且也没有遮挡。
所以接下去就直接遍历训练集的所有图片找到有关键点标注的图片并且修改成 bounding box 了,代码贴在下面,完整的代码可以在我的 GitHub 仓库找到
import json
import numpy as np
import os.path as osp
root = '/NAS_REMOTE/PUBLIC/data/coco2017/annotations'
json_file = osp.join(root, 'person_keypoints_train2017.json')
scale_w = 1.55
scale_h = 1.33
results = []
image_name = []
json_list = []
annto_cnt = 0
viz_mode = True
with open(json_file, 'r') as f:
f = json.load(f)
annotations = f['annotations']
annotations = sorted(annotations, key=lambda x: x['image_id'])
for item in annotations[:1000]:
image_id = item['image_id']
keypoints = item['keypoints']
num_keypoints = item['num_keypoints']
fn = '# ' + str(image_id).zfill(12) + '.jpg'
left_shoulder = 5*3
right_shoulder = 6*3
left_hip = 11*3
right_hip = 12*3
if num_keypoints < 4:
continue
flag1 = keypoints[left_shoulder+2]
flag2 = keypoints[right_shoulder+2]
flag3 = keypoints[left_hip+2]
flag4 = keypoints[right_hip+2]
if flag1 == 0 or flag2 == 0 or flag3 == 0 or flag4 == 0:
continue
x1 = keypoints[left_shoulder]
y1 = keypoints[left_shoulder+1]
x2 = keypoints[right_shoulder]
y2 = keypoints[right_shoulder+1]
x3 = keypoints[left_hip]
y3 = keypoints[left_hip+1]
x4 = keypoints[right_hip]
y4 = keypoints[right_hip+1]
x5 = (x1 + x2 + x3 + x4) / 4
y5 = (y1 + y2 + y3 + y4) / 4
bbox_x = min(x1, x2, x3, x4)
bbox_y = min(y1, y2, y3, y4)
bbox_w = max(x1, x2, x3, x4) - bbox_x
bbox_h = max(y1, y2, y3, y4) - bbox_y
bbox_ctl_x = bbox_x + bbox_w / 2
bbox_ctl_y = bbox_y + bbox_h / 2
bbox_w = scale_w * bbox_w
bbox_h = scale_h * bbox_h
bbox_x = bbox_ctl_x - bbox_w / 2
bbox_y = bbox_ctl_y - bbox_h / 2
bbox_x = max(0, bbox_x)
bbox_y = max(0, bbox_y)
if viz_mode:
data = {}
data['img_id'] = str(image_id)
data['bbox_x'] = bbox_x
data['bbox_y'] = bbox_y
data['bbox_w'] = bbox_w
data['bbox_h'] = bbox_h
data['left_shoulder'] = (x1, y1)
data['right_shoulder'] = (x2, y2)
data['left_hip'] = (x3, y3)
data['right_hip'] = (x4, y4)
data['center_point'] = (x5, y5)
json_list.append(data)
else:
if flag1 == 1 or flag2 == 1 or flag3 == 1 or flag4 == 1:
data = bbox_x, bbox_y, bbox_w, bbox_h, -1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1
else:
data = bbox_x, bbox_y, bbox_w, bbox_h,\
x1, y1, 2, x2, y2, 2, x5, y5, 2, x3, y3, 2, x4, y4, 2
results = np.array([data])
with open('result.txt', 'a') as f:
if image_id in image_name:
pass
else:
image_name.append(image_id)
f.write(fn+'\n')
np.savetxt(f, results, delimiter=' ')
annto_cnt += 1
print('anno_cnt', annto_cnt)
if viz_mode:
with open('results/viz_data.json', 'w') as f:
json.dump(json_list, f)
最终展示出来的一些效果如下所示

