安装
1 先创建一个名为 open-mmlab 的虚拟环境并激活
$ conda create -n open-mmlab python=3.7 -y
$ conda activate open-mmlab
2 安装合适版本的 pytorch(去官网按照自己的 cuda 版本进行安装)
$ conda install -c pytorch pytorch torchvision -y
3 安装 mmcv(看清楚自己的 CUDA 版本)
$ pip install mmcv-full==latest+torch1.5.0+cu101 -f https://openmmlab.oss-accelerate.aliyuncs.com/mmcv/dist/index.html
(或者直接用下面这条命令也可以)
$ pip install mmcv-full
4 克隆 mmdetection 仓库并进入
$ git clone https://github.com/open-mmlab/mmdetection.git
$ cd mmdetection
5 安装依赖以及 mmdetection
$ pip install -r requirements/build.txt
$ pip install -v -e . # or "python setup.py develop"
使用
mmdetection 里面分了好多目录,将相关的文件都放在了同一个文件夹中,下面就会介绍一些重要的文件夹
├── configs
├── data
├── demo
├── docker
├── docs
├── mmdet
├── mmdet.egg-info
├── requirementsd
├── resources
├── tests
├── tools
└── work_dirs
configs
├── albu_example
├── atss
├── _base_
├── carafe
├── cascade_rcnn
├── centripetalnet
├── cityscapes
├── cornernet
├── ………………
├── dcn
├── deepfashion
与训练和测试有关的配置都在 configs 文件夹中,找到对应算法的 config 文件,config 的命名格式如下
{model}_[model setting]_{backbone}_{neck}_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset}
对应的解释如下:

mmdet
mmdet 这个文件夹是非常重要的,算法源码几乎都在里面,所以重点要知道里面每个文件夹里有什么东西
├── apis
├── core
├── datasets
├── __init__.py
├── models
├── ops
├── __pycache__
├── utils
└── version.py
core
core 里面是针对大多数任务都会有的核心操作,比如 anchor 的生成和分配,mAP 计算,bbox 的编码解码,后处理 nms 等等
├── anchor
├── bbox
├── evaluation
├── export
├── fp16
├── __init__.py
├── mask
├── post_processing
├── __pycache__
└── utils
datasets
datasets 里面包含了对数据集的处理,尤其是 pipelines 这个文件夹,里面集成了很多个类用来表示对数据集的一些通用操作,如 pad,randomflip,resize 等等,如果想定义一个新的数据集,就得在这里新建一个 py 文件,并且在 __init__.py 里面添加这个文件以注册
├── builder.py
├── cityscapes.py
├── coco.py
├── custom.py
├── dataset_wrappers.py
├── deepfashion.py
├── __init__.py
├── lvis.py
├── pipelines
├── __pycache__
├── samplers
├── utils.py
├── voc.py
├── wider_face.py
└── xml_style.py
models
models 这个文件夹更加重要,可以说是对我们来说整个 mmdetection 最需要认真看的地方,里面全是一些实现的细节。backbone 里面是分类骨干网络的实现,xx_heads 是网络头部的实现,neck 是连接 backbone 和 heads 的部分,而 detector 里面就是某一个具体的算法的配置,loss 里面实现了各种损失函数。这些都是部件,在 config 的配置中就可以将这些东西组成在一起形成一个具体的算法
├── backbones
├── builder.py
├── dense_heads
├── detectors
├── __init__.py
├── losses
├── necks
├── __pycache__
├── roi_heads
└── utils
tools
├── analyze_logs.py
├── benchmark.py
├── browse_dataset.py
├── coco_error_analysis.py
├── convert_datasets
├── detectron2pytorch.py
├── dist_test.sh
├── dist_train.sh
├── eval_metric.py
├── get_flops.py
├── print_config.py
├── ………………
├── train.py
└── upgrade_model_version.py
train
在 tools 文件夹里有很多有用的工具,比如说训练测试以及可视化曲线、计算模型参数量的代码。用得十分频繁,下面拿训练 maskrcnn 来做个例子,训练的时候我们就可以用下面命令
CUDA_VISIBLE_DEVICES=2 python tools/train.py configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py
mmdetection 就会按照 py 文件中的配置找到相对应的模型配置、训练策略配置以及数据集配置,然后就会开始训练,训练的日志以及模型保存在 work_dirs 这个文件夹中。
test
测试的时候就可以用到 tools/test.py 来测试模型的 mAP 等等,以及可视化样本,上面训练完成 maskrcnn 之后就可以通过下面的命令来测试性能,这里我是创建了一个新的文件夹 show_dirs 用来保存处理后的图片样本
CUDA_VISIBLE_DEVICES=2 python tools/test.py configs/mask_rcnn/mask_rcnn_r50_fpn_1x_coco.py work_dirs/mask_rcnn_r50_fpn_1x_coco/latest.pth --show-dir show_dirs/maskrcnn --eval segm

全部的测试选项代码如下
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show] [--cfg-options]

analyze_logs
然后我们可以用训练的日志文件来生成 loss 曲线等,这个在 tools/analyze_logs.py 文件中有提及,挺方便的
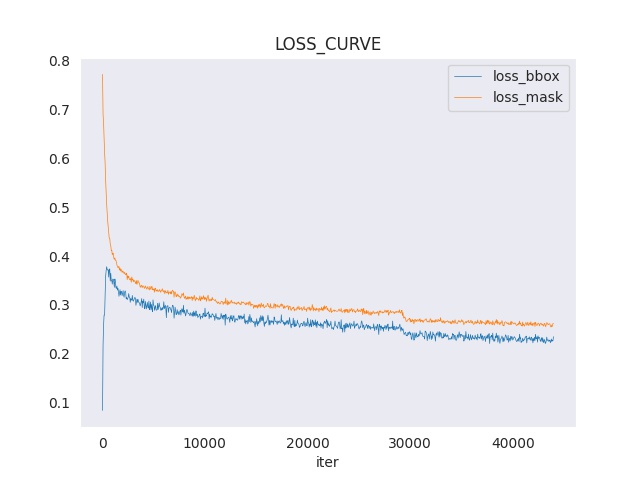
CUDA_VISIBLE_DEVICES=2 python tools/analyze_logs.py plot_curve work_dirs/mask_rcnn_r50_fpn_1x_coco/20200912_024022.log.json --keys loss_bbox loss_mask --legend loss_bbox loss_mask --title LOSS_CURVE --out loss.jpg
然后就会得到这样的一张 loss 曲线图片
全部的代码选项如下
python tools/analyze_logs.py plot_curve [--keys ${KEYS}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
browse_dataset 可视化数据集
想要可视化数据集的标注是否正确时,可以用这个脚本,默认会画出所给的 config 文件的训练集的标注,很方便
修改代码
讲一下我在修改 fcos 的过程中学习到的 mmdetection 处理流程以及相应代码的解释
// TODO
一些相关概念
workflow
workflow = [('train', 1)] is mean train only. workflow = [('train', 3),('val',1)] is mean that first train 3 epochs, then val 1 epcoh, then loop. 这个是继承了 default_runtime.py
[(‘train’, 1)] 和 [(‘train’, 1), (‘val’, 1)] 是不一样的,后者会在训完一轮后再训验证集,会计算验证集上的 loss,这对模型分析很有用(如 ResNet 里面就有这么干)
train
训练流程 (train.py) ,先是注册好模型数据集
model = build_detector(
cfg.model, train_cfg=cfg.train_cfg, test_cfg=cfg.test_cfg)
datasets = [build_dataset(cfg.data.train)]
然后直接调用 train_detector
train_detector(
model,
datasets,
cfg,
distributed=distributed,
validate=(not args.no_validate),
timestamp=timestamp,
meta=meta)
train_detector 在 mmdet/apis/train.py, 这里面 先是注册优化器,然后再定义了一个 runner,这个 runner 是训练的主要东西
optimizer = build_optimizer(model, cfg.optimizer)
runner = EpochBasedRunner(
model,
optimizer=optimizer,
work_dir=cfg.work_dir,
logger=logger,
meta=meta)
之后定义各种针对 runner 的 Hook 钩子函数
runner.register_training_hooks(cfg.lr_config, optimizer_config,
cfg.checkpoint_config, cfg.log_config,
cfg.get('momentum_config', None))
runner.register_hook(eval_hook(val_dataloader, **eval_cfg))
相关的东西定义完之后呢,就调用 runner.run 函数,开始真正训练代码,这个函数在 mmcv 的 runner/epoch_based_runner.py 里面,根据数据集以及 workflow 和迭代次数做出训练
def run(self, data_loaders, workflow, max_epochs, **kwargs):
同样的,真正的训练函数和验证函数都在这个文件里面
def train(self, data_loader, **kwargs):
def val(self, data_loader, **kwargs):
如何判断是进行 train 还是 val 就在下面这段代码里面,其实就是根据 workflow 来找到关键字 train 或者 val ,将 epoch_runner 定义为关键字,刚好这个类里面又有以 train 和 val 命名的函数,所以直接调用 epoch_runner 就相当于训练或测试了几个 epoch
while self.epoch < max_epochs:
for i, flow in enumerate(workflow):
mode, epochs = flow
if isinstance(mode, str): # self.train()
if not hasattr(self, mode):
raise ValueError(
f'runner has no method named "{mode}" to run an '
'epoch')
epoch_runner = getattr(self, mode)
else:
raise TypeError(
'mode in workflow must be a str, but got {}'.format(
type(mode)))
for _ in range(epochs):
if mode == 'train' and self.epoch >= max_epochs:
break
epoch_runner(data_loaders[i], **kwargs)
forward 相关
无论是什么检测器,在 mmdetection 中可以简单被分成 backbone、neck、head 这三个部分,只要搞懂组成某个检测器的这三个部分是怎么前向传播的就能够明白原理。首先给出很重要的七个文件,都在 mmdet/models 里面,最重要的打上 * 号
* base.py
single_stage.py
two_stage.py
* base_dense_head.py
* base_roi_head.py
anchor_head.py
anchor_free_head.py
想看网络是怎么前向传播的就得看 forward 函数,基类 BaseDetector 当中的 forward 方法调用了 self.forward_train ,如下面所示
当时还没理解透,其实前向传播是利用了 mmcv 中的机制,在 mmcv 的源码中写到了,以下是 EpochBasedRunner,可以看到,他是调用了 self.model.train_step 这个步骤得到前向结果,这个 self.model 就是一个 nn.Module 模型。
@RUNNERS.register_module()
class EpochBasedRunner(BaseRunner):
"""Epoch-based Runner.
This runner train models epoch by epoch.
"""
def run_iter(self, data_batch, train_mode, **kwargs):
if self.batch_processor is not None:
outputs = self.batch_processor(
self.model, data_batch, train_mode=train_mode, **kwargs)
elif train_mode:
outputs = self.model.train_step(data_batch, self.optimizer,
**kwargs)
else:
outputs = self.model.val_step(data_batch, self.optimizer, **kwargs)
if not isinstance(outputs, dict):
raise TypeError('"batch_processor()" or "model.train_step()"'
'and "model.val_step()" must return a dict')
if 'log_vars' in outputs:
self.log_buffer.update(outputs['log_vars'], outputs['num_samples'])
self.outputs = outputs
在基类 BaseDetector 当中实现了 train_step 方法,这里用了 self(**data),self 指的是自己本身,所以就调用了 __call__ 方法,在 nn.Module 模型中,__call__ 调用的是 forward 方法,所以这个函数其实就是调用模型的 forward 方法
def train_step(self, data, optimizer):
"""The iteration step during training.
This method defines an iteration step during training, except for the
back propagation and optimizer updating, which are done in an optimizer
hook. Note that in some complicated cases or models, the whole process
including back propagation and optimizer updating is also defined in
this method, such as GAN.
"""
losses = self(**data)
loss, log_vars = self._parse_losses(losses)
outputs = dict(
loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
return outputs
接下去看看 BaseDetector 的 forward 方法,其实他又调用了 forward_train 函数,所以这个函数用来计算 loss,一般子类要重写这个函数,train_step 函数没有需求的话一般不用重写。
@auto_fp16(apply_to=('img', ))
def forward(self, img, img_metas, return_loss=True, **kwargs):
"""Calls either :func:`forward_train` or :func:`forward_test` depending
on whether ``return_loss`` is ``True``.
Note this setting will change the expected inputs. When
``return_loss=True``, img and img_meta are single-nested (i.e. Tensor
and List[dict]), and when ``resturn_loss=False``, img and img_meta
should be double nested (i.e. List[Tensor], List[List[dict]]), with
the outer list indicating test time augmentations.
"""
if return_loss:
return self.forward_train(img, img_metas, **kwargs)
else:
return self.forward_test(img, img_metas, **kwargs)
forward_train 在 BaseDetector 中是个抽象方法,需要被子类实现,也就是继承 BaseDetector 的 SingleStageDetector 和 TwoStageDetector,因此主要看的就是这两个类中的 forward_train 函数
在 SingleStageDetector 中,是如下结构,获取特征后让 bbox_head 进行 forward_train ,所以后面还得去看 bbox_head 的 forward_train 函数
def forward_train(self,
img,
img_metas,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None):
x = self.extract_feat(img)
losses = self.bbox_head.forward_train(x, img, img_metas, gt_bboxes,
gt_labels,
gt_bboxes_ignore)
return losses
在 TwoStageDetector 中,是如下结构,获取特征后,如果输入有 with_rpn 的话,就让 rpn_head 进行 forward_train 得到 proposals,如果没有的话,就自己传入 proposals 参数,不管有没有 rpn ,后面都得调用 roi_head 的 forward_train 函数,所以,掌握一个规律,一般 roi_head 都用在二阶段算法中,且配合 rpn_head 一起用,而一阶段几乎都是 bbox_head
def forward_train(self,
img,
img_metas,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None,
gt_masks=None,
proposals=None,
**kwargs):
x = self.extract_feat(img)
losses = dict()
if self.with_rpn:
proposal_cfg = self.train_cfg.get('rpn_proposal',
self.test_cfg.rpn)
rpn_losses, proposal_list = self.rpn_head.forward_train(
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=gt_bboxes_ignore,
proposal_cfg=proposal_cfg)
losses.update(rpn_losses)
else:
proposal_list = proposals
roi_losses = self.roi_head.forward_train(x, img_metas, proposal_list,
gt_bboxes, gt_labels,
gt_bboxes_ignore, gt_masks,
**kwargs)
losses.update(roi_losses)
return losses
下面我们拿 RetinaNet 来做示范,这是个一阶段 Anchor-based 算法, bbox_head 是 RetinaHead ,打开文件就发现这是继承 class RetinaHead(AnchorHead): 的,但是并没有在里面看到 forward_train 函数,于是我们就点开他的父类 AnchorHead,里面也没有 forward_train 函数,只有 forward 函数,同时这个类又是继承 class AnchorHead(BaseDenseHead): 的,所以我们又打开 BaseDenseHead 来看看,终于找到了!
不过这里的 self(x) 写得有点迷,之前一直没看懂,后来问实验室俊良大哥才知道,解释一下,x 是经过了 fpn 后的五个特征图,是一个 tuple,在 tuple 里面是 5 个 size 为 [bs, c, h, w] 的 featmap。self(x) 调用自己,也就是调用 call 方法,这里没有 call 方法,所以调用的是 nn.Module.call 方法,nn.Module.call 调用了 nn.Module.forward 方法,但是这里没有 forward 方法,别急,继承这个类的 AnchorHead 里面有,所以就用了 AnchorHead 里面的 forward 函数
def forward_train(self,
x,
img,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
outs = self(x)
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
if proposal_cfg is None:
return losses
else:
proposal_list = self.get_bboxes(*outs, img_metas, cfg=proposal_cfg)
return losses, proposal_list
来看看 AnchorHead 的 forward 函数,你又会发现它调用了 forward_single 这个函数
def forward(self, feats):
return multi_apply(self.forward_single, feats)
然而 AnchorHead 这个类里面没有写这个函数,别急,它在 RetinaHead 里面,绕来绕去绕了很多,不过,有了这些分析之后你就会发现,以后修改类似的 head 时就只需要修改顶层的 forward_single 函数了,其他的大家都一样
def forward_single(self, x):
cls_feat = x
reg_feat = x
for cls_conv in self.cls_convs:
cls_feat = cls_conv(cls_feat)
for reg_conv in self.reg_convs:
reg_feat = reg_conv(reg_feat)
cls_score = self.retina_cls(cls_feat)
bbox_pred = self.retina_reg(reg_feat)
return cls_score, bbox_pred
除此之外,在 AnchorHead 里面计算 loss 时还调用了 self.loss ,还是一样的分析,看 loss 函数在哪一层类上实现,就去看相应的实现代码,有些是 loss_single,有些是 loss,注意分清区别。到此,一阶段 Anchor-based 的 head 前向过程就分析得差不多了,一阶段 Anchor-free 算法也是一样的,就是找 forward_train 函数,然后要注意是否在顶层类重写了父类方法
另外,以 Faster RCNN 来分析一下二阶段的算法前向流程,二阶段会复杂点,有很多 head,比如 rpn_head 是 RPNHead,roi_head 是 StandardRoIHead,按照前面的分析,先让 rpn_head 前向,再让 roi_head 前向。在 RPNHEAD 里面没有找到 forward_train 函数,一路找过去,还是在 BaseDenseHead 里面找到,所以还是得找到哪里实现了 forward 函数,哪里实现了 loss 函数
def forward_train(self,
x,
img,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
outs = self(x)
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
if proposal_cfg is None:
return losses
else:
proposal_list = self.get_bboxes(*outs, img_metas, cfg=proposal_cfg)
return losses, proposal_list
有了前面的分析,这个也不难,在 AnchorHead 中找到了 forward 函数,并且也有 forward_single 函数
def forward_single(self, x):
cls_score = self.conv_cls(x)
bbox_pred = self.conv_reg(x)
return cls_score, bbox_pred
def forward(self, feats):
return multi_apply(self.forward_single, feats)
但是这还不行,因为 RPNHead 重写了 forward_single 函数,所以要以 RPNHead 中的 forward_single 为准,发现没有,好像二阶段各种算法也就只修改了 forward_single 这个函数,和一阶段是一样的
def forward_single(self, x):
"""Forward feature map of a single scale level."""
x = self.rpn_conv(x)
x = F.relu(x, inplace=True)
rpn_cls_score = self.rpn_cls(x)
rpn_bbox_pred = self.rpn_reg(x)
return rpn_cls_score, rpn_bbox_pred
StandardRoIHead 接收 RPNHead 得到的 proposals 继续前向,经过 RoIPooling 得到大小相同的 RoI,然后进行分类回归得到最终输出,这个直接就在顶层类实现了,所以不用跳着找
def forward_train(self,
x,
img_metas,
proposal_list,
gt_bboxes,
gt_labels,
gt_bboxes_ignore=None,
gt_masks=None):
前向过程
model 在 forward 之后出来会有个 loss,mmdetection 老版本是在 mmdet/apis/train.py 里面运用 batch_processor 来将这些 loss 解析成单个 loss,新版本的 mmdet 已经将 batch_processor 弃用了,用了 train_step 和 val_step 来代替,这两个函数在 models/detectors/base.py 里面。
def train_step(self, data, optimizer):
losses = self(**data)
loss, log_vars = self._parse_losses(losses)
outputs = dict(
loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
return outputs
def _parse_losses(self, losses):
log_vars = ORDERED_DICT
for loss_name, loss_value in losses.items():
if isinstance(loss_value, torch.Tensor):
log_vars[loss_name] = loss_value.mean()
elif isinstance(loss_value, list):
log_vars[loss_name] = sum(_loss.mean() for _loss in loss_value)
else:
raise TypeError(
f'{loss_name} is not a tensor or list of tensors')
loss = sum(_value for _key, _value in log_vars.items()
if 'loss' in _key)
log_vars['loss'] = loss
for loss_name, loss_value in log_vars.items():
if dist.is_available() and dist.is_initialized():
loss_value = loss_value.data.clone()
dist.all_reduce(loss_value.div_(dist.get_world_size()))
log_vars[loss_name] = loss_value.item()
return loss, log_vars
训练自己的数据集
VOC-style
我有一个 HumanParts 数据集,它的标注格式是符合 VOC 的,但是跟 VOC 又不是完全一样,有些变动,为了在 mmdetection 上训练这个数据集,我需要在 dataset 模块中新注册一个类,首先我的数据集的拓扑是下面这样子的,图片在 Images 里面,标注在 Annotation 里面,训练集和测试集的分类 txt 文件在 ImageSets 里面,和 VOC 的命名不是太一样。
├── Annotations
├── Images
├── ImageSets
├── Json_Annos
└── tools
在 dataset 中可以看到 VOC 是继承了 XMLDataset ,
@DATASETS.register_module()
class VOCDataset(XMLDataset):
那我们也新建一个类继承 XMLDataset,并且把数据集的类别写进 CLASSES
@DATASETS.register_module()
class HumanPartsDataset(XMLDataset):
CLASSES = ('face', 'person', 'hand')
然后再看看 xml 格式的标注是怎么被 load 进来的,在 XMLDataset 中有 load_annotations 方法,可以看到,他是默认按照标准 VOC 存放文件的位置来写这个函数的
def load_annotations(self, ann_file):
data_infos = []
img_ids = mmcv.list_from_file(ann_file)
for img_id in img_ids:
filename = f'JPEGImages/{img_id}.jpg'
xml_path = osp.join(self.img_prefix, 'Annotations',
f'{img_id}.xml')
tree = ET.parse(xml_path)
root = tree.getroot()
size = root.find('size')
if size is not None:
width = int(size.find('width').text)
height = int(size.find('height').text)
else:
img_path = osp.join(self.img_prefix, 'JPEGImages',
'{}.jpg'.format(img_id))
img = Image.open(img_path)
width, height = img.size
data_infos.append(
dict(id=img_id, filename=filename, width=width, height=height))
return data_infos
所以我们在新的类里面要重写这个函数,把 path 换成我们自己的。到这儿其实就差不多了,但是类里面还有个 self.ds_name 成员,这个是用来确实每个类对应的名称的,在 evaluation 的时候会用到,如果 self.ds_name 错了的话,就默认会使用类里面自定义的 CLASSES,这个在哪里改呢,在 mmdet/core/evaluation/class_names.py 里面修改,这里面写上了所有数据集对应的类别名称。
def humanparts_classes():
return [
'face', 'person', 'hand',
]
dataset_aliases = {
'voc': ['voc', 'pascal_voc', 'voc07', 'voc12'],
'imagenet_det': ['det', 'imagenet_det', 'ilsvrc_det'],
'imagenet_vid': ['vid', 'imagenet_vid', 'ilsvrc_vid'],
'coco': ['coco', 'mscoco', 'ms_coco'],
'wider_face': ['WIDERFaceDataset', 'wider_face', 'WIDERFace'],
'cityscapes': ['cityscapes'],
'humanparts': ['humanparts'],
}
def get_classes(dataset):
"""Get class names of a dataset."""
alias2name = {}
for name, aliases in dataset_aliases.items():
for alias in aliases:
alias2name[alias] = name
if mmcv.is_str(dataset):
if dataset in alias2name:
labels = eval(alias2name[dataset] + '_classes()')
else:
raise ValueError(f'Unrecognized dataset: {dataset}')
else:
raise TypeError(f'dataset must a str, but got {type(dataset)}')
return labels
然后对检测器添加 config 就行了,一个样例如下:
dataset_type = 'HumanPartsDataset'
data_root = '/kevin_data/Human-Parts/'
img_norm_cfg = dict(
mean=[127.5, 127.5, 127.5], std=[1.0, 1.0, 1.0], to_rgb=True)
train_pipeline = [
...
]
test_pipeline = [
...
]
data = dict(
samples_per_gpu=16,
workers_per_gpu=8,
train=dict(
type='RepeatDataset',
times=3,
dataset=dict(
type=dataset_type,
ann_file=data_root + 'ImageSets/privpersonpart_train.txt',
img_prefix=data_root,
pipeline=train_pipeline)),
val=dict(
type=dataset_type,
ann_file=data_root + 'ImageSets/privpersonpart_val.txt',
img_prefix=data_root,
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'ImageSets/privpersonpart_val.txt',
img_prefix=data_root,
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='mAP')
最后注意,训练的时候还得把 bbox_head 的 num_classes 变成相应的类别数,比如这里就是 3 而不是 80.
mmdet 中 Hook feature
在做蒸馏的时候会遇到对 teacher 和 student 对应的特征进行蒸馏的需求,可能会用到 hook 机制,hook 机制其实就是拦截一个 nn.Module 模块的输出内容,在 mmdet 中也很好做到
import numpy as np
from mmdet.apis import init_detector, inference_detector
config_file = '/data1/opt/.cache/matlab/.mmdet/configs/retinanet/retinanet_r50_fpn_1x_coco.py'
device = 'cuda:0'
model = init_detector(config_file, None, device=device)
dummy_img = np.ones((600,600,3)).astype(np.uint8)
results = []
def my_forward_hook(module, inp, outp):
print('module: ', module)
print('input: ', inp)
print('output: ', outp.shape)
results.append(outp)
module = dict(model.named_modules())['neck']
module.register_forward_hook(my_forward_hook)
res = inference_detector(model, dummy_img)
自定义导入模型
mmdet 定义模型的时候就是在相应的模型文件夹中新建一个文件并且注册
import torch.nn as nn
from ..builder import BACKBONES
@BACKBONES.register_module()
class MobileNet(nn.Module):
def __init__(self, arg1, arg2):
pass
def forward(self, x): # should return a tuple
pass
使用的时候可以有两种方式,一种是直接在对应的 __init__.py 文件中添加
from .mobilenet import MobileNet
另一种就是在 config 文件中用 custom_imports 来导入模块,这样子的话就可以不用改动源码,只需要在 config 中添加就行
custom_imports = dict(
imports=['mmdet.models.backbones.mobilenet'],
allow_failed_imports=False)
img_metas
dict_keys([‘filename’, ‘ori_filename’, ‘ori_shape’, ‘img_shape’, ‘pad_shape’, ‘scale_factor’, ‘flip’, ‘flip_direction’, ‘img_norm_cfg’, ‘batch_input_shape’])
- “img_shape”: shape of the image input to the network as a tuple (h, w, c). Note that images may be zero padded on the bottom/right if the batch tensor is larger than this shape.
- “scale_factor”: a float indicating the preprocessing scale
- “flip”: a boolean indicating if image flip transform was used
- “filename”: path to the image file
- “ori_shape”: original shape of the image as a tuple (h, w, c)
- “pad_shape”: image shape after padding
- “img_norm_cfg”: a dict of normalization information:
- mean - per channel mean subtraction
- std - per channel std divisor
- to_rgb - bool indicating if bgr was converted to rgb
Registry机制
mmdet 中的注册机制其实就是将 string 字符串和 一个 class 建立起一种映射,只要我们输入一个字符串,就能够得到相对应的类,很方便,用的时候只需要 build 一下就可以了。贴一下官网的例子(mmcv 出 bug 了,命令行里运行不了,等他们解决完 bug 再来更新)
跟下面这样子的话呢就可以注册一个 converter 大类,假设是在 converters/builder.py 文件中
from mmcv.utils import Registry
# create a registry for converters
CONVERTERS = Registry('converter')
然后我们引入这个文件,并且新建一个 converters/converter1.py 文件,相当于在 converter 大分支中实现了一个具体的类,只需要在类的前面用 Registry 的装饰器就行了
from .builder import CONVERTERS
# use the registry to manage the module
@CONVERTERS.register_module()
class Converter1(object):
def __init__(self, a, b):
self.a = a
self.b = b
这样我们就将 Converter1 这个字符串和 Converter1 这个类建立起了一个连接,当我们想要实例化这个类的时候我们直接调用 Registry 的 build 方法,传入对应字符串和参数就行了
converter_cfg = dict(type='Converter1', a=a_value, b=b_value)
converter = CONVERTERS.build(converter_cfg)
制作自己的数据集在mmdet中训练
TODO 有空再补
labelme转coco数据集 - 一届书生 - 博客园 (cnblogs.com)
使用mmdetection训练自己的coco数据集(免费分享自制数据集文件) - 一届书生 - 博客园 (cnblogs.com)
一些比较好的教程
mmdetection可视化一些 Anchor 和 Proposal
reference
https://mmdetection.readthedocs.io/en/latest