preface
本篇文章介绍一下目标检测中常用的一些评估准则,大家跑 yolo 的时候可能看着一堆输出不知道啥意思,希望这篇文章能够解决大家的疑惑,主要是翻译 GitHub 上的一个 repo,原文是英文写的,链接在这里,写的挺不错,就翻译过来给英文不好的同学看看,另外还加了几个项目中没有提到的准则
不同的竞赛有不同的指标
- PASCAL VOC Challenge 提供了 Matlab 脚本,以便评估检测到的目标的质量, 竞赛的参与者可以在提交结果之前使用提供的 Matlab 脚本来测量其检测的准确性。 当前 PASCAL VOC 目标检测挑战所使用的度量标准是
Precision x Recall曲线和Average Precision也就是 PR 曲线和平均精确度 - COCO Detection Challenge 使用不同的指标来评估不同算法的目标检测的准确性。点击此处可以找到说明 12 种度量标准的文档,这些度量标准用于表征 COCO 上目标检测器的性能。 该竞赛提供了 Python 和 Matlab 代码,因此用户可以在提交结果之前验证分数并且还需要将结果转换为比赛所需的格式。
- Google Open Images Dataset V4 Competition 使用 500 个类的平均平均精度 (mAP) 来评估目标检测任务。
- ImageNet Object Localization Challenge 定义了每个图像的 error,其中考虑了类别以及真实标签与 Bounding Box 之间的 IOU, 总误差计算方法为所有测试数据集中最小误差的平均值(俺也没理解清楚这这句话到底啥意思==)
重要的概念
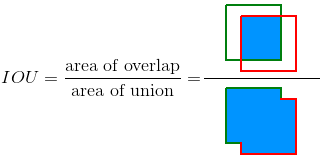
Intersection Over Union (IOU)
这个好理解,做目标检测的时候,我们会提前标注数据,用一个 Box 将目标框起来,训练的时候也会生成 Bounding Box,检测定位得准不准就看生成的 BBox 和标注的 Box(也叫 ground truth)的重叠区域。IOU 就是二者的重叠区域面积与二者并集面积之比,越接近1 说明定位效果越好
TP,FP,FN,TN
这四个是评估准则的一些基本概念:
-
True Positive (TP): 一次正确的检测. Detection with IOU ≥ threshold
-
False Positive (FP): 一次错误的检测. Detection with IOU < threshold
-
False Negative (FN): 一个目标没有被检测出来
-
True Negative (TN): 这个指标一般不会去用,它相当于 BBox 框在没有目标的地方
threshold: 阈值,取决于具体准则,一般是 0.5,也有 0.75,0.95
前面三个都是在基于 GroundTruth 下的三种情况,TN 是检测在了一个没有 GroundTruth 的地方
Precision精确度
精确度是模型仅识别相关目标的能力,它是所有有效检测中正确检测的百分比
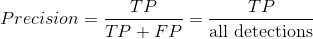
Recall召回率
召回率是模型找到所有 GroundTruth Bbox 的能力,它是在所有相关的 GroundTruth Bbox 中检测到 TF 的百分比,并由下式给出
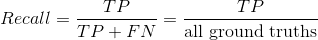
一些评估方法
Precision x Recall curve - PR曲线
PR 曲线是一种很好的评估目标检测器性能的方法,因为通过绘制每个目标类的曲线可以改变置信度。如果特定类的目标检测器的 Precision 随着 Recall 的增加而仍然保持较高,则认为它是好的,这意味着如果更改置信阈值,则其 Precision 和 Recall 仍然很高。另一种判别一个好的目标检测器的方法是寻找一种只能识别相关目标 (0FP = 高 Precision ) 的检测器,找到所有的 GroundTruth (0FN = 高 Recall )。
一个较差的目标检测器需要增加被检测对象的数量 (增加 FP = 较低的 Precision ) 来检索所有 GroundTruth (高 Recall ) 。这就是为什么PR 曲线通常以高 Precision 值开始,并随着 Recall 的增加而降低。
下面引自知乎用户陈子豪对PR 曲线 的通俗化理解:
precision和recall的含义, preicision是在你认为的正样本中, 有多大比例真的是正样本, recall则是在真正的正样本中, 有多少被你找到了。
问题核心: 我们需要一个对于score的threshold, 为什么呢? 比如在一个bounding box里, 我识别出来鸭子的score最高, 可是他也只有0.1, 那么他真的是鸭子吗? 很可能他还是负样本。 所以我们需要一个阈值, 如果识别出了鸭子而且分数大于这个阈值才真的说他是正样本, 否则他是负样本
那么threshold到底是怎么影响precision和recall的呢? 我们还是用鸭子的例子
- 如果threshold太高, prediction非常严格, 所以我们认为是鸭子的基本都是鸭子,precision就高了;但也因为筛选太严格, 我们也放过了一些score比较低的鸭子, 所以recall就低了
- 如果threshold太低, 什么都会被当成鸭子, precision就会很低, recall就会很高
这样我们就明确了threshold确实对鸭子的precision和recall产生影响和变化的趋势, 也就带来了思考, precision不是一个绝对的东西,而是相对threshold而改变的东西, recall同理, 那么单个用precision来作为标准判断, 就不合适。 这是一场precision与recall之间的trade off, 用一组固定值表述不够全面, 因为我们根据不同的threshold, 可以取到不同(也可能相同)的precision recall值。 这样想的话对于每个threshold,我们都有(precision, recall)的pair, 也就有了precision和recall之间的curve关系
有了这么一条precision-recall curve, 他衡量着两个有价值的判断标准, precision和recall的关系, 那么不如两个一起动态考虑, 就有了鸭子这个class的Average Precision, 即curve下的面积, 他可以充分的表示在这个model中, precision和recall的总体优劣。
Average Precision - AP平均精度
另一种比较对象检测器性能的方法是计算PR 曲线下的面积 (AUC) 。由于AP曲线通常是呈 zig-zag 之字形曲线,在同一张图中比较不同的曲线(不同的检测器)通常不是一件容易的事——因为这些曲线往往相互交叉。这就是为什么平均精度(AP),一个以数值形式的度量方法,也可以帮助我们比较不同的检测器。在实践中,AP 是所有 Recall 在 0 到 1 之间的平均精度。
拿官网的例子来说吧,下图绿框是某类的 15 个 groundtruth 值,24 个红框是预测出来的结果,并且也给出了相应的置信度
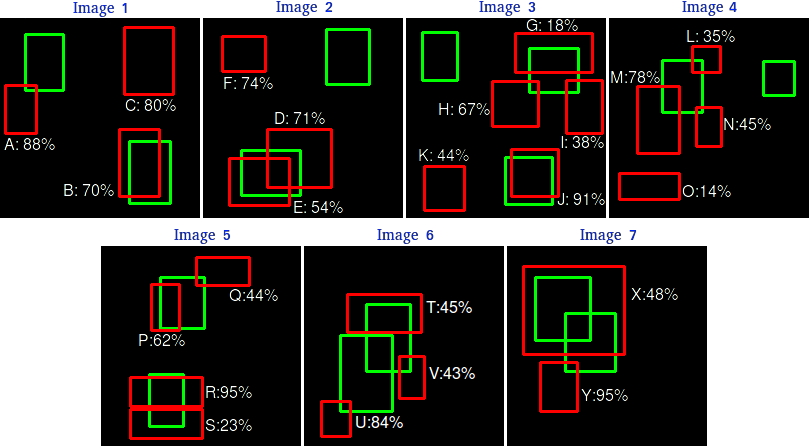
下面我们就用 IOU 为 30% 作为评估的阈值,如果检测结果和 groundtruth 的 IOU 超过 30%,则此次检测为 TP,否则就是 FP,我们通过肉眼观察一下可以看出大概哪些检测是 TP ,哪些是 FP
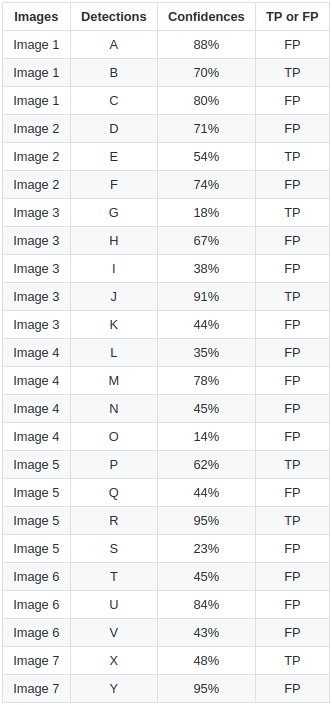
然后我们按照置信度从高到底进行排序,统计 TP 和 FP 的数量,进行 Precision 和 Recall 的计算,因为 groundtruth 就是 15,所以按照上面 Recall 的公式,直接用 TP 除以 groundtruth 的值就是 Recall 的值
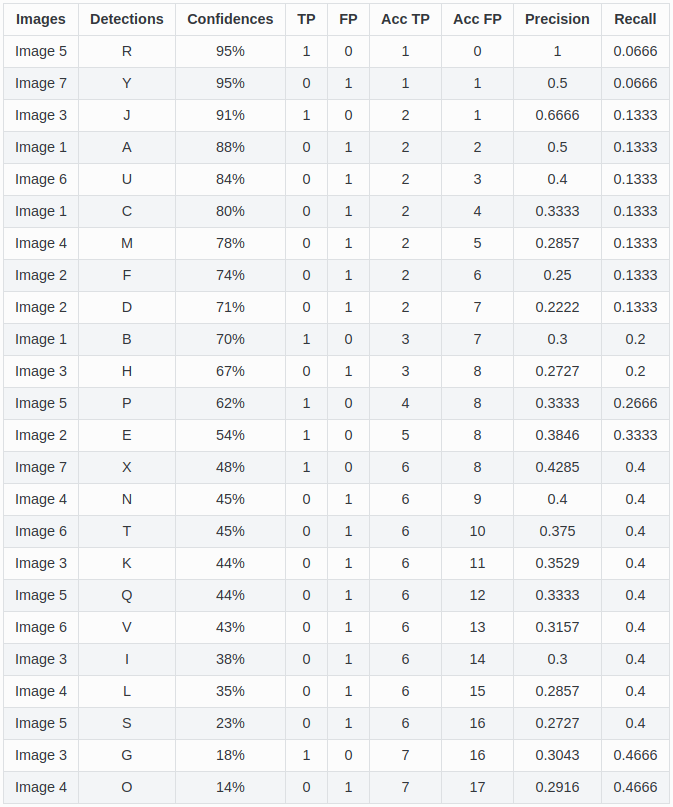
最后在坐标轴上对每个 Precision-Recall pair 进行绘图,得到 PR曲线,就是下面这个折线图
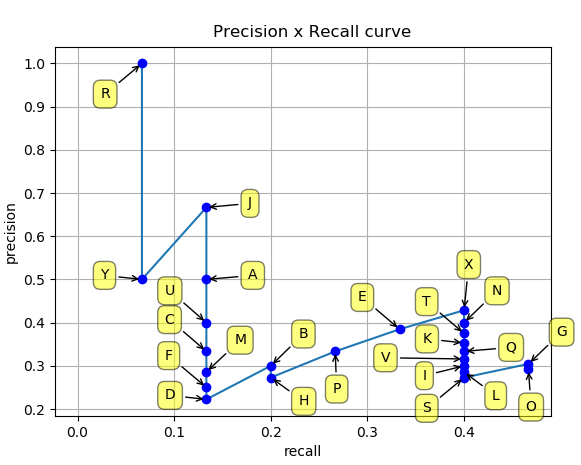
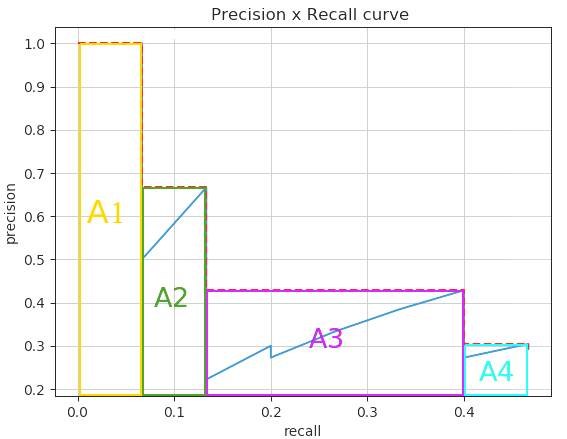
然后 AP 的值就是 PR曲线 下方围成的面积的值,而且取得是相隔最高的点(emmm 不知道怎么解释,看下面的图吧)
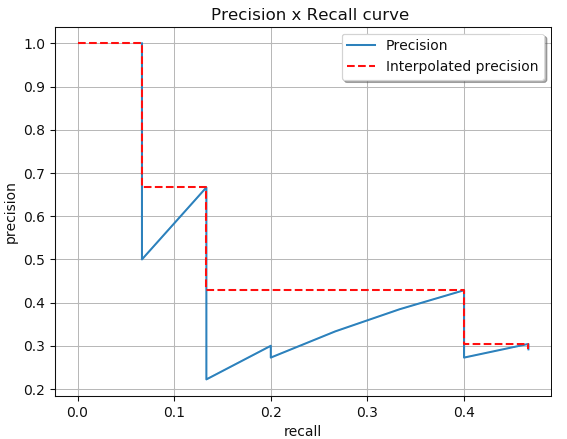
将上图的面积分成几个矩形分别计算面积,加起来就是 AP 值

mean Average Precision - mAP平均精度
AP 是对单个 class 进行的测量,将所有的 class 的 AP 值都加起来除以 class 的个数,得到的就是 mAP 平均精度
reference
https://github.com/rafaelpadilla/Object-Detection-Metrics