preface
这节课介绍了几个常见的卷积神经网络的架构,从结构上学习神经网络的构成,包括 AlexNet,LeNet,VGG,GoogLeNet,ResNet,这些网络都是在之前的 ImageNet 挑战中获得过第一名网络结构,值得我们好好学习一下。现在很多的神经网络框架里都集成了这些框架,但是建议还是手动实现一下哈
Transfer Learning
在实际中,很少有人会去从零开始去训练出一个CNN。普遍的做法都是在一个大的数据集比如ImageNet 进行预训练一个CNN模型,然后在这使用这个模型作为固定特征提取器或者网络的初始化权重应用在特定的任务中。也就是说,站在巨人的肩膀上干活。可以在 ImageNet 上训练的 model 后面的全连接层上做手脚,只训练后面几层 FC ,固定前面那些卷积层的 W ,也可以给所有层的 W 都进行微调 Fine-tuning
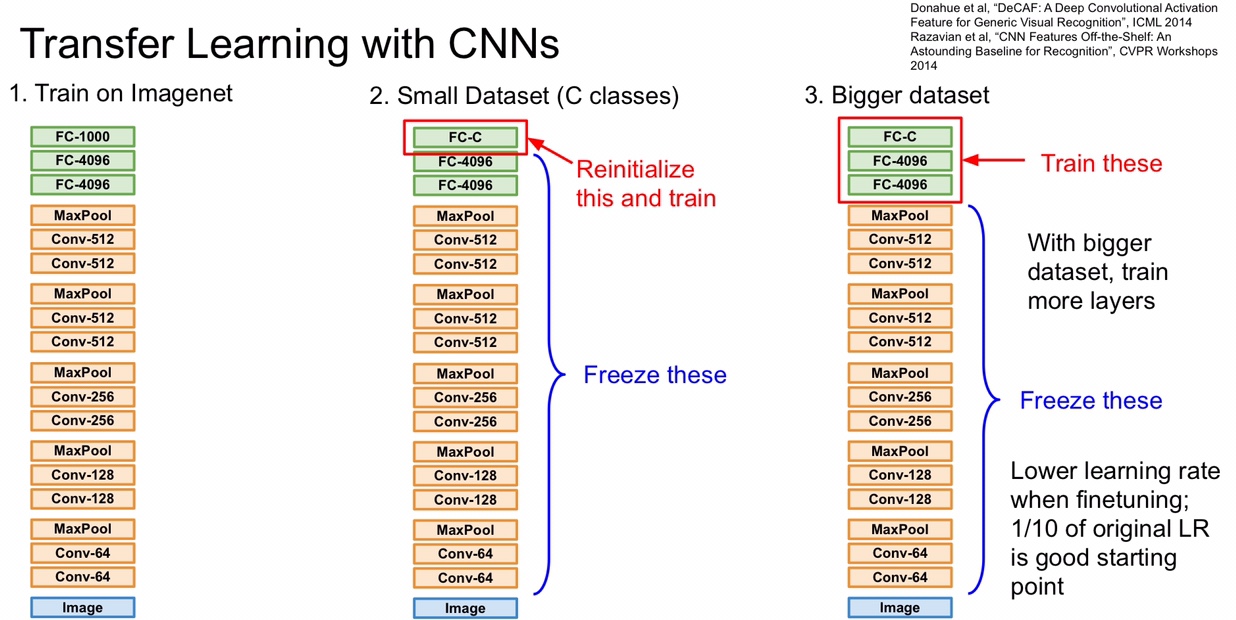
AlexNet
首先是 AlexNet,这在 2012 年的比赛中获得了冠军,也是从 AlexNet 开始,深度学习再一次流行了起来,下面这个便是 AlexNet 的结构:
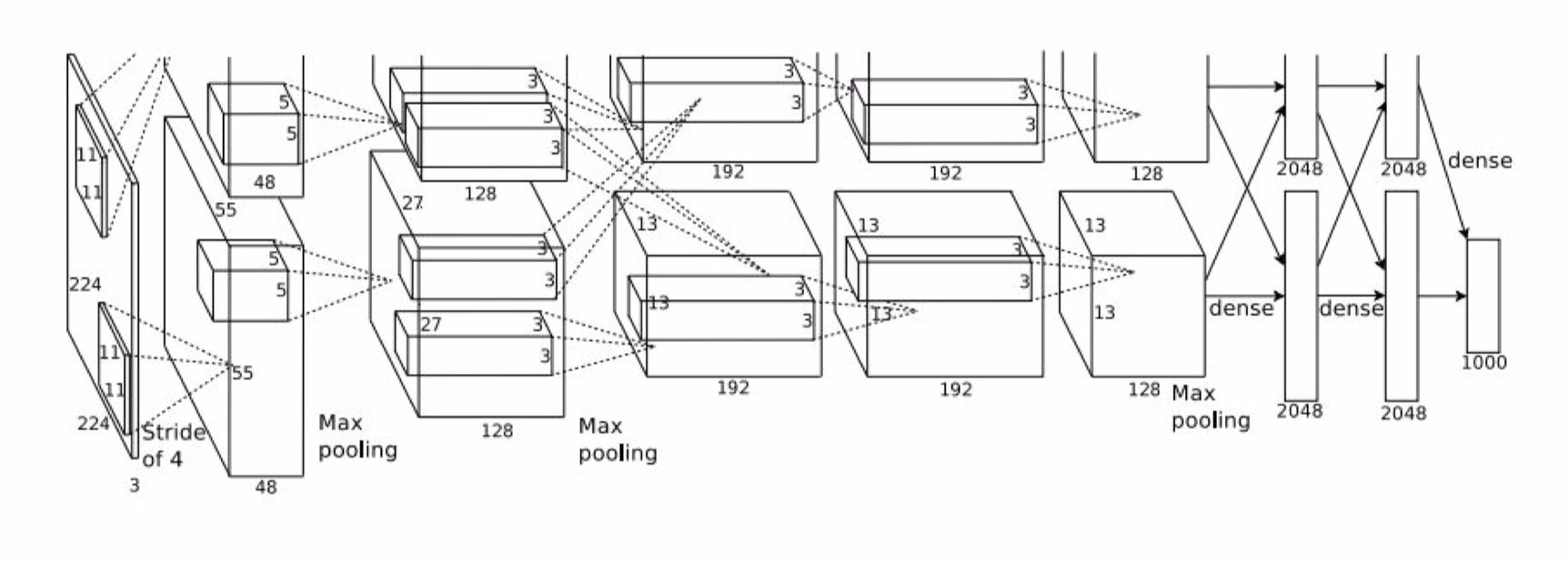
AlexNet 的输入是 227 x 227 x 3 的一张三维图,经过一个 CONV,一个 POOL,一个 NORM,一个 CONV,一个 POOL,一个 NORM,三个 CONV,一个 POOL,三个 FC 之后得到所有类别的 score,有关的 layer 如下,下面我们一起来分析一下
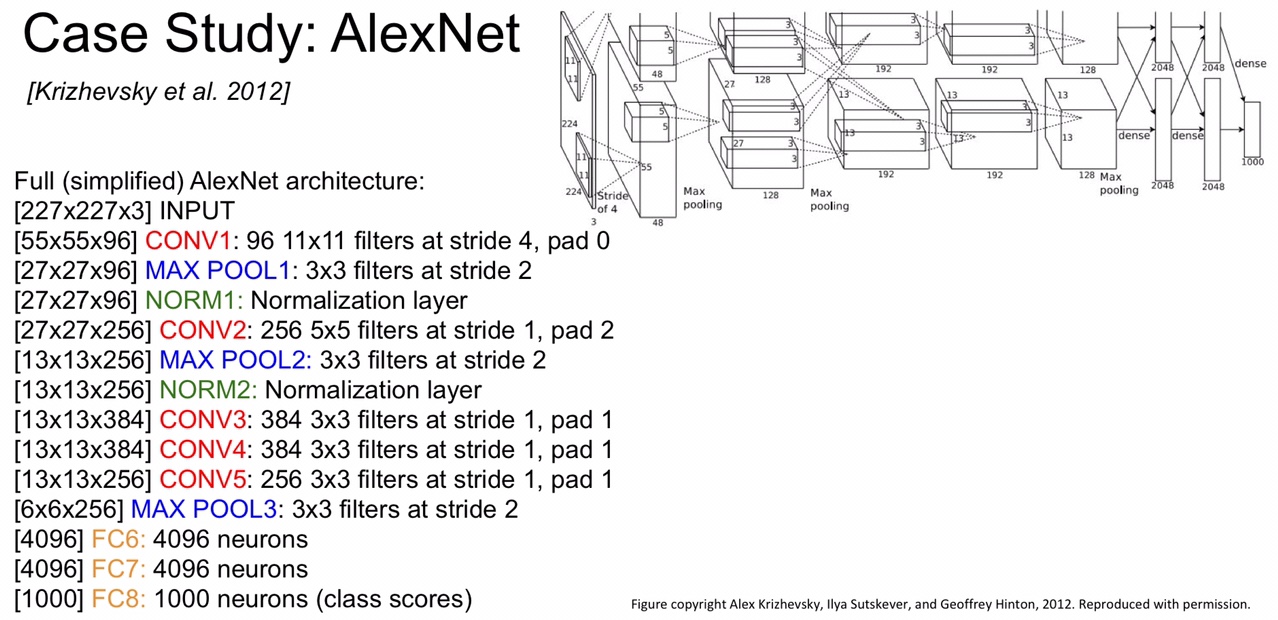
上面说了网络的输入是 227 x 227 x 3,经过第一层卷积(96 个 11 x 11 的步长为 4 的 kernel)后,size 变成了 (227 - 11)/ 4 + 1 = 55 ,因为是 96 个卷积核堆叠,所以经过第一层卷积后的 volume 变成了 55 x 55 x 96,紧接着卷积层的就是最大池化层,计算方法还是一样的,池化层不改变图像的深度,size 变成了 (55 - 3)/ 2 + 1 = 27,NORM 归一层不会改变图像尺寸,如果卷积层有 padding 的话计算 size 的公式就是 (size - 1 + 2 x padding)/ stride + 1 。到了全连接层,这里说一下,全连接层就是用很多个 volume 相同的卷积核对上层所得的图像进行卷积,在这里,上面的池化层得到的输出为 6 x 6 x 256,而第一层 FC 需要有 4096 个神经元(这个不是算出来的,这是作者自定义的),所以这里我们需要用 4096 个 6 x 6 x 256 的卷积核,之后的 FC 也是一样的,最后一层 FC 的神经元的个数要是所有 class 的个数,ImageNet 是 1000 个类。
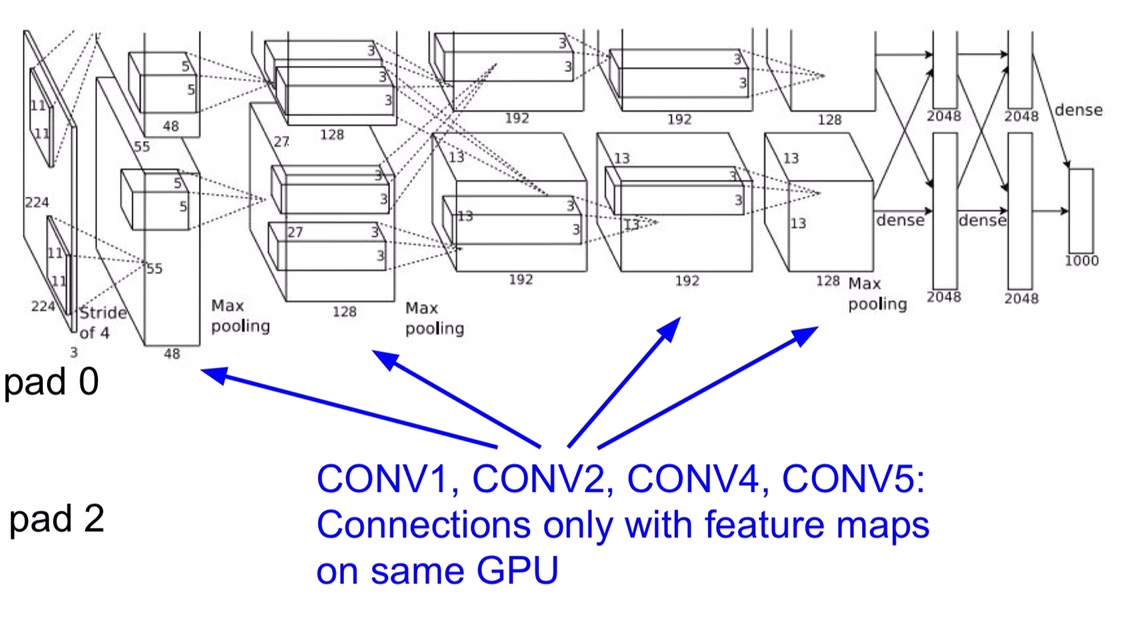
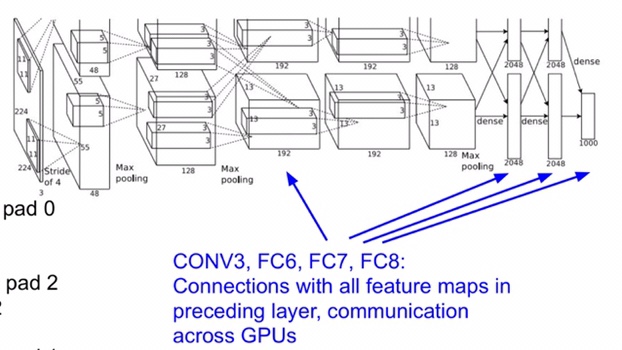
至于为什么网络结构图会有上下两块呢,因为那个时代的硬件跟不上,显卡只有 3 GB,装不下网络中这么多参数,所以作者将参数分别放在了两块 GPU 上训练,我们再来看看 AlexNet 的架构
可以看到有些 layer 的参数只在上面或者下面进行传播,比如第一、二、四、五层 CONV,有些 layer 又同时在上下都有共享,比如第三层 CONV 和最后三层 FC。经过第一层 CONV 卷积后的图片尺寸是 55 x 55 x 96 的,由于是在两张显卡上,所以是 55 x 55 x 48 x 2 这样的一个形式,另外,在图中的输入层是 224 x 224 的,但是其实是 227 的,这里可能是有错误。
既然说到了参数,下面我们来计算一下整个 AlexNet 需要多大的参数量(不计入偏置 bias)。首先,第一层 CONV 用了 11 x 11 x 3 x 96 = 34848 个参数,POOL 层是超参数,不需要训练得到,因此 POOL 层所需参数为 0,NORM 也不需要额外训练参数,第二层 CONV 用到了 5 x 5 x 96 x 256 = 614400 个参数,第三层 CONV 需要 3 x 3 x 256 x 384 = 884736 个参数,第四层 CONV 需要 3 x 3 x 384 x 384 = 1327104 个参数,第五层 CONV 需要 3 x 3 x 256 x 256 = 589824 个参数,第一层 FC 需要 6 x 6 x 256 x 4096 = 37748736 个参数,第二层 FC 需要 1 x 1 x 4096 x 4096 = 16777216 个参数,第三层 FC 需要 1 x 1 x 4096 x 1000 = 4096000 个参数。一共加起来是 60m 的参数量。
可以看到第一层 FC 需要训练的参数特别可怕,这也是后来人们抛弃 FC 层的原因,需要训练的参数量实在是太多了。另外,在三层 FC 之后应该还有一层 softmax,用来将 class 转化成相应的概率。
VGG
VGG 的思想是用更小的卷积核以及更深层的网络来训练模型,它有 VGG16 和 VGG19 两个版本,主要是层数的不同,下面是 VGG 的网络结构(这里的应该有误,3 x 3 CONV,256 那里应该少了一层)

可以看到 VGG 用的卷积核都是 3 x 3 的,这是因为多个小卷积核堆叠等于一个大的卷积核的效果,并且参数量更少,更深的非线性层也可以让网络学习到更多东西。三个 3 x 3 的卷积核的 effective receptive field(中文好像叫感受野)就等于一个 7 x 7 的卷积核的 effective receptive field,看张图就明白是为什么了
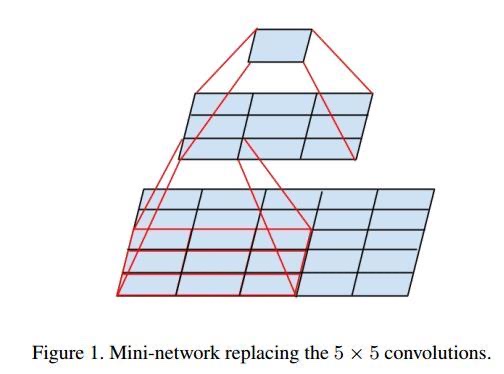
这张图是用 2 个 3 x 3 的卷积核代替一个 5 x 5 的卷积核,假设输入的图像是 5 x 5 的,如果直接用 5 x 5 的卷积核的话卷积出来是变成了一个 1 x 1 的图像,用两个 3 x 3 的话,第一个 3 x 3 卷积出来变成 3 x 3 的图,再用第二个 3 x 3 卷积一下就变成了 1 x 1 的图像,和用一个 5 x 5 卷积核效果是一样的
VGG 的输入是 224 x 224 x 3 的图像,我们来看看 VGG 所需要的参数,老师还将所需的内存也写出来了。计算参数的方法在 AlexNet 那里就已经写过了,这里不再推导,计算内存就直接将每一层的图像的 volume 相乘再相加就好了,因为每一层得到的 output 都是临时量,要存储到内存中,可以看到,正向传播一次就要 96mb (24 * 4 ,4 是因为一个像素占用 4 个 bytes)的内存,加上反向传播就是两倍了,最耗内存的就是开始的几层 CONV ,因为那时的图像尺寸大,到后面尺寸变小了就不会消耗那么多内存。参数量最多的还是在全连接层,这个在 AlexNet 里面也说过了,近些年的网络很多都取消了 FC 层。

GoogLeNet
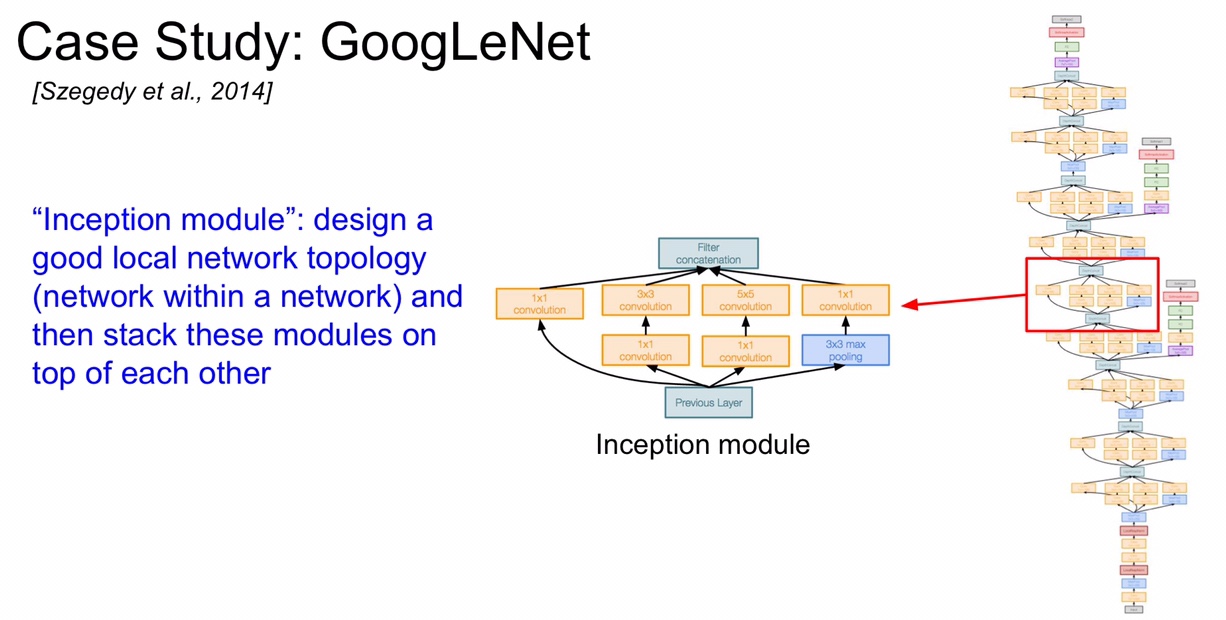
GoogLeNet 为了致敬 LeNet,特意将名字中的 L 大写,它的创新点就是提出了 “Inception” 的概念,就是让上层的 output 输入到平行的几个 layer 中,创造出尺寸相同,深度可能不同的几个 output,然后通过 Filter concatenation 将这几个 output 的深度堆叠起来形成真正的 output。GoogLeNet 中运用了很多个 Inception 模块堆叠起来。
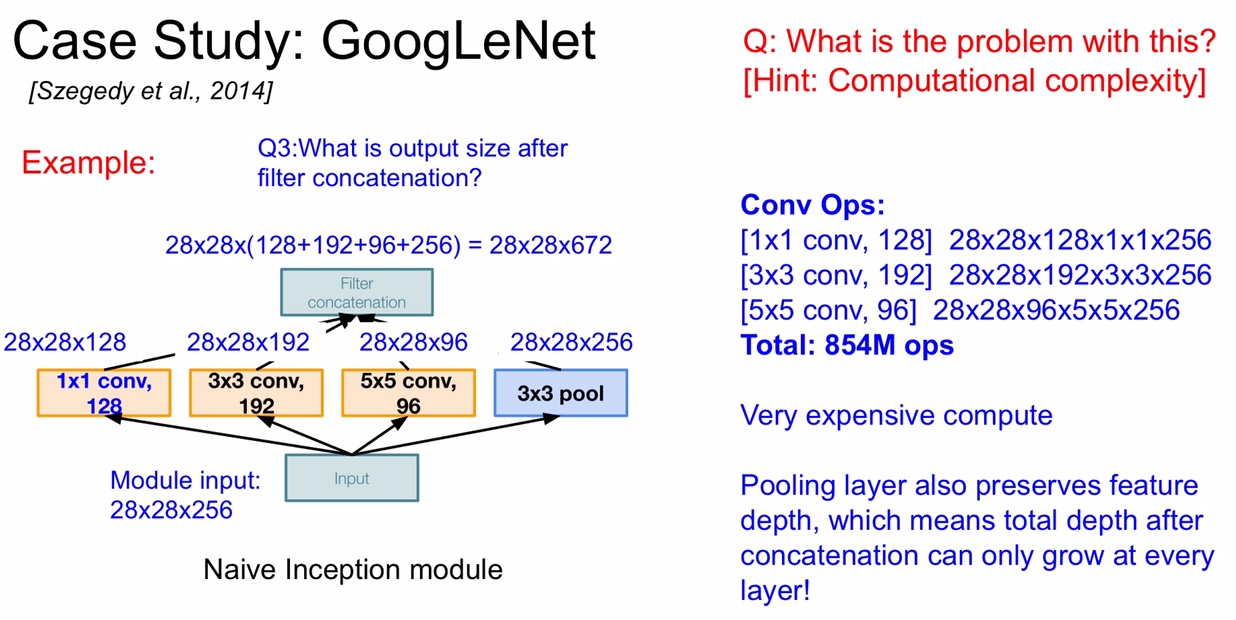
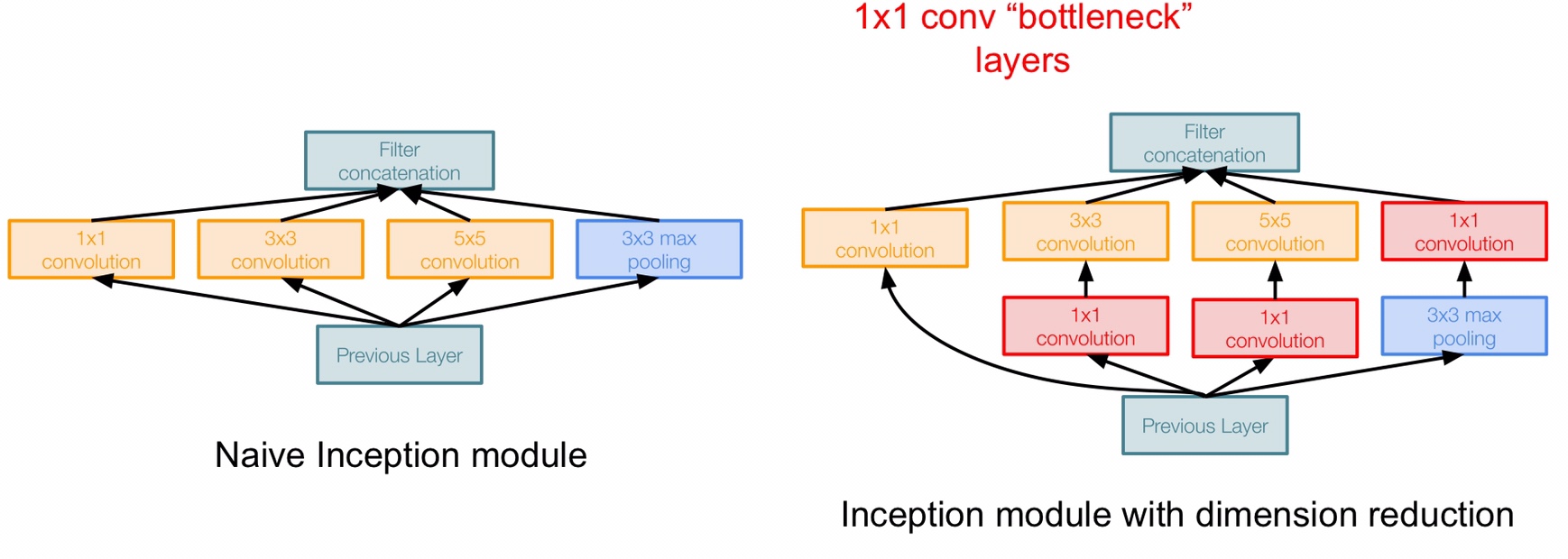
说到了 Inception 就得介绍一下原理,不过在此之前先说一下 naive 版本的 Inception,就是下面这张图了,假设输入的图像是 28 x 28 x 256,经过左边的 128 个 1 x 1 的卷积核卷积后就变成了 28 x 28 x 128,跟它平行的 layer 为了能够堆叠,卷积后的 size 也是 28 x 28(应该要使用 padding),深度随着卷积核的个数而定,最后经过 Filter concatenation 堆叠,最终 output 的尺寸为 28 x 28 x 672 。那么这样的 naive Inception 有什么缺点呢?那就是运算量太大了,下图中右边展示出了平行的卷积层的运算量,一共达到了 854M 次运算,是非常大的运算量,并且 POOL 层不会改变 input 的深度,也就是说,output 的深度只会比 input 更深,并且随着 Inception 的堆叠,图像深度会越来越深
为了解决这个问题,Google 用的是 “bottleneck layer” ,也就是 size 为 1 x 1 的卷积核,bottleneck 就是为了改变图像的深度,右边就是 GoogLeNet 使用的 Inception,在左边的 naive Inception 的基础上加了三个 bottleneck layer
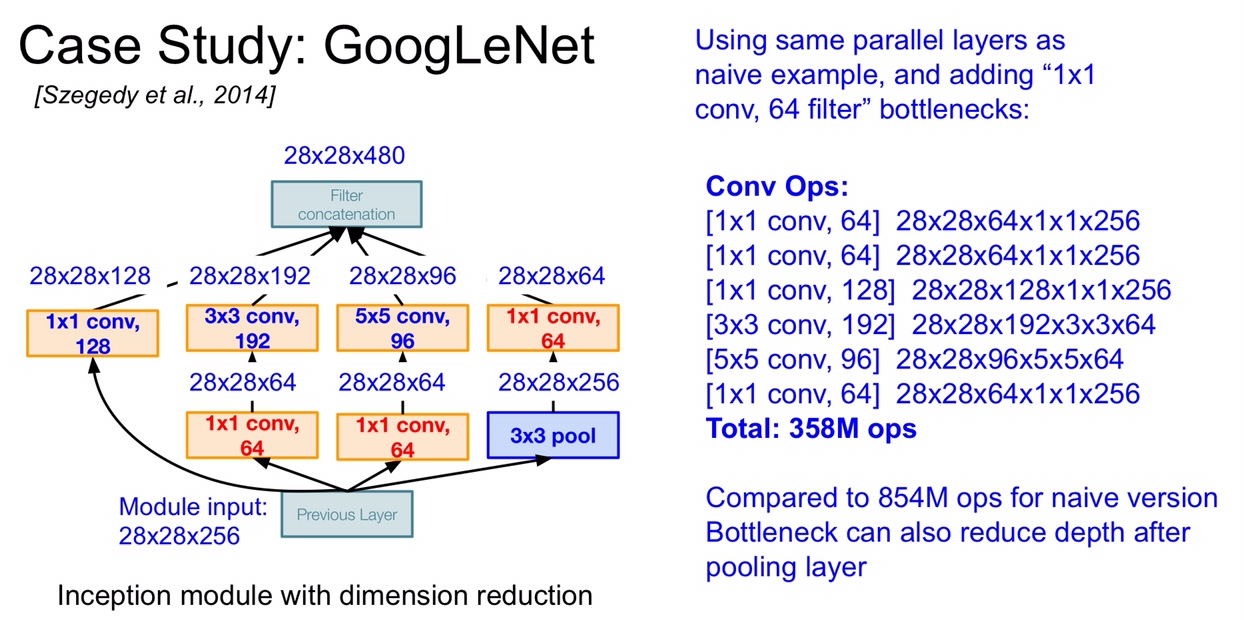
用了这种 Inception 之后,再按照之前的计算方法计算一下 output 的 volume 和总体的运算量,output 的 volume 为 28 x 28 x 480,深度比之前的少了两百多,总的运算量只有 358M ,相比 naive Inception 提升了一倍多,很高效。值得注意的是,一个 Inception layer 相当于两个 CONV layer,在计算 GoogLeNet 层数的时候是这样计算的。
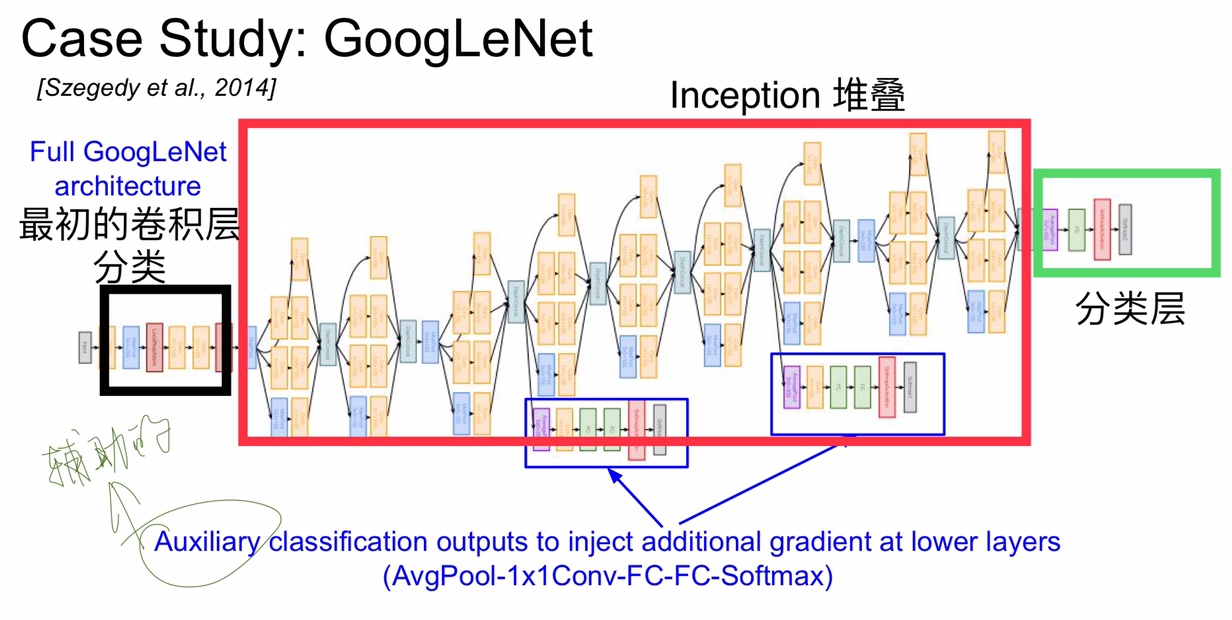
下面全局看一下 GoogLeNet 的结构,最初的几层是卷积池化层,然后就是不断的 Inception 堆叠,最后用一个 Global Average POOL 和 一层 FC 接一个 softmax 进行分类,这里在 FC 之前用 Global Average POOL 代替了原本的 FC ,降低了原本 FC 带来的巨大参数量。另外还有两个辅助的分类层用来防止网络传播过程中梯度消失,用来给浅层的网络添加额外的梯度,一共是 22 层(不计算辅助层)
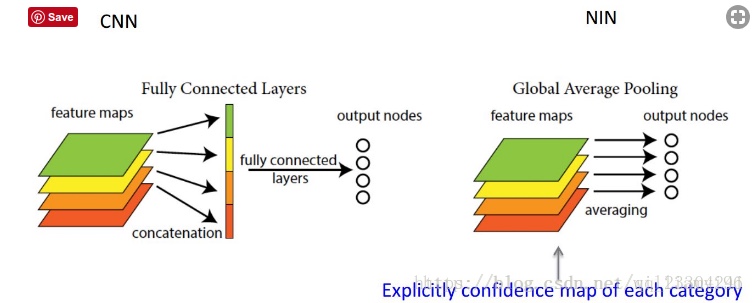
插一嘴 Global Average POOL (简称GAP)和 FC 的区别,下面是 NIN(network in network)里的图片,GAP 可以对整个网路在结构上做正则化防止过拟合,直接赋予了每个channel实际的内别意义。
global average pooling 与 average pooling 的差别就在 “global” 这一个字眼上。global 与 local 在字面上都是用来形容 pooling 窗口区域的。 local 是取 feature map 的一个子区域求平均值,然后滑动这个子区域; global 就是对整个 feature map 求平均值了
ResNet
下面到了恺明大神的 ResNet 了,ResNet 的出现是一个巨大的成功,现在很多人都在 ResNet 的基础上进行改进。近来大家的观点是网络越深能够学习到的东西越多,但是太深的网络可能会造成梯度消失,导致后面的网络什么也没学到,我们试着不断用 CONV 层堆叠成一个网络看看训练和测试的效果,发现 56 层的网络在训练和测试时的 error 都比 20 层的要高,这并不是因为过拟合了,而是因为越深层的网络越难优化。
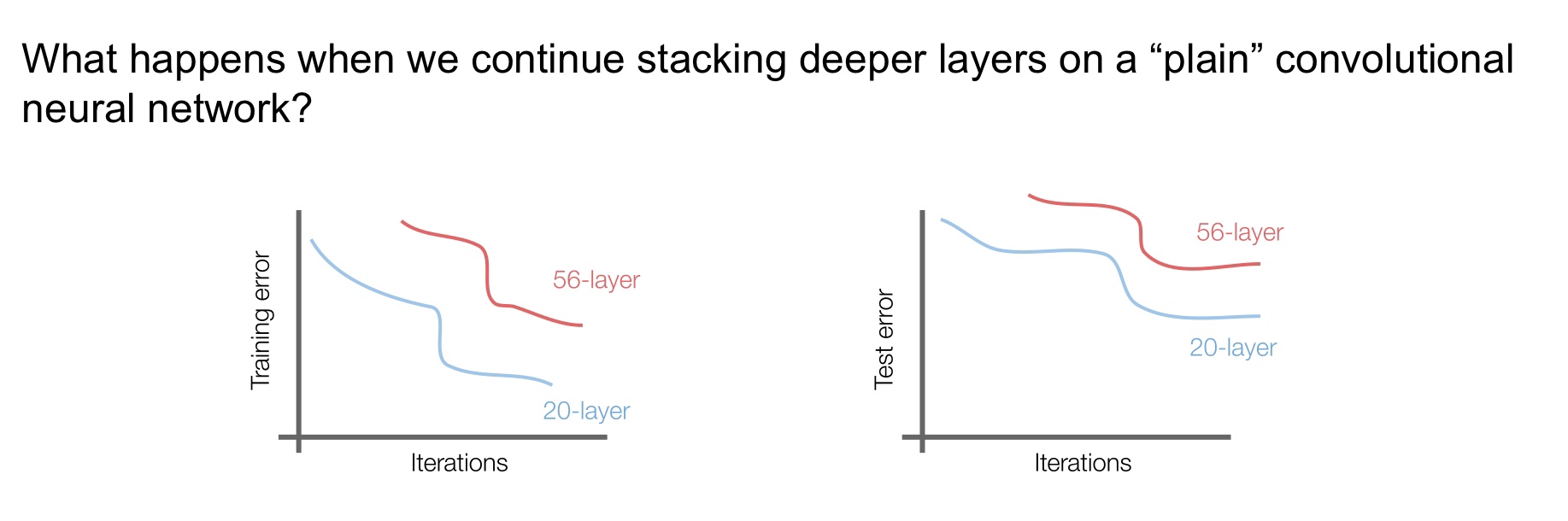
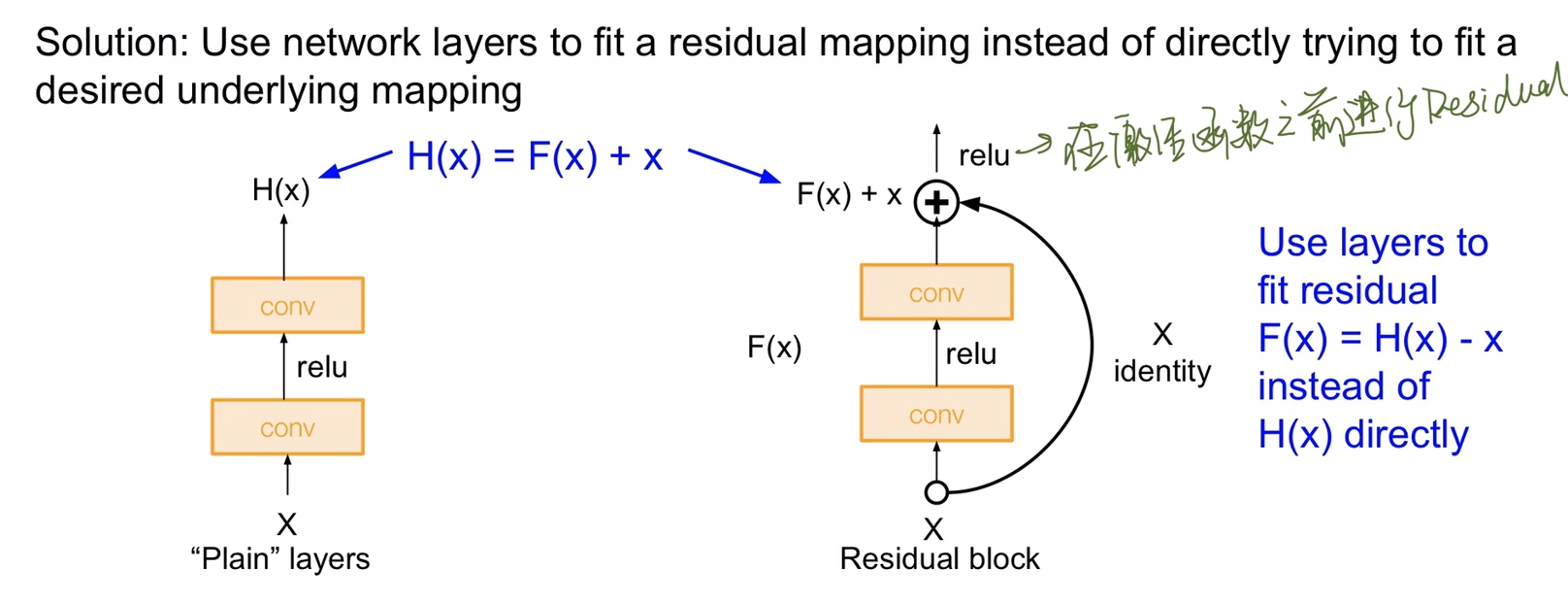
直接用卷积层堆叠的效果不好,但是人们想深层网络的表现起码也得和浅层的表现差不多才好吧,既然是因为参数不好优化,那么是否可以将前面浅层学到的东西以某种方式映射到后面的层中呢?ResNet 的创新点就在于使用了 Residual Block 残差块,下面是它与单纯的卷积堆叠的对比图。
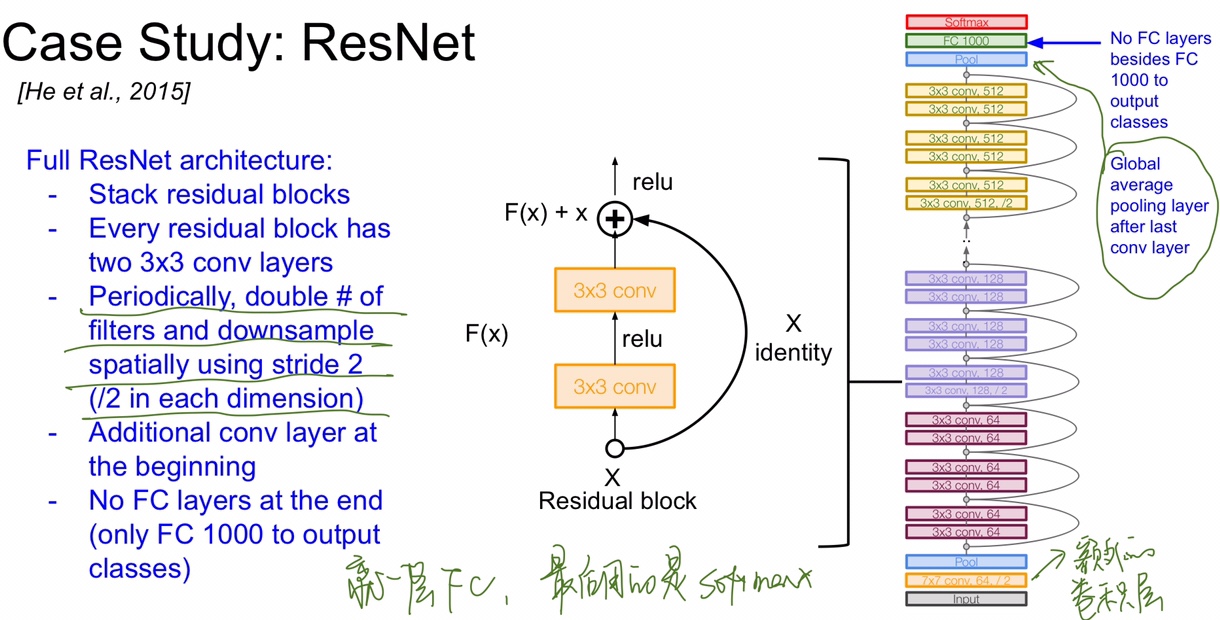
ResNet 大体的结构就是靠着很多个残差块堆叠起来的,在 ImageNet 比赛上足足有 152 层,非常深,每一个残差块里面都有两个 3 x 3 的卷积层,ResNet 的总体框架如图,其中的卷积层有些出现了 /2 代表 stride 为 2,其最后也是和 GoogLeNet 一样选择用 Global Average Pooling 而不是 FC,减少了很多参数量。
现在很多人都在 ResNet 的结构上进行了改动,比如当 ResNet 的层数更深时,可以适当改变残差块的结构,学习 GoogLeNet 加入 bottleneck layer 减少运算量

课程的最后也给出了在实际中训练 ResNet 的建议

tips
ImageNet 从 2017 年以后就没有单独举办了,现在大家比赛都去 kaggle 了。
reference
https://blog.csdn.net/qq_23304241/article/details/80292859