preface
作为不经常打开公文通的人,我经常会错过很多重要的信息,自己也是已经尝到了苦头,我就在想,反正我每天都会 check 自己的邮箱,能不能写个爬虫把公文通的内容爬下来,然后通过邮件每天定时发送给我自己,这样我就不会错过公文通了,项目驱动型学习,说干就干
爬取网页
爬取的网页是我们学校公文通,长这样,一页大概有几百条记录,并且只有一页,因此,感觉很简单,直接用 requests + BeautifulSoup 黄金搭档进行爬取就可以了,原本以为还要用 cookies 验证身份,后来发现不用 cookies 也可以,那就更加简单了
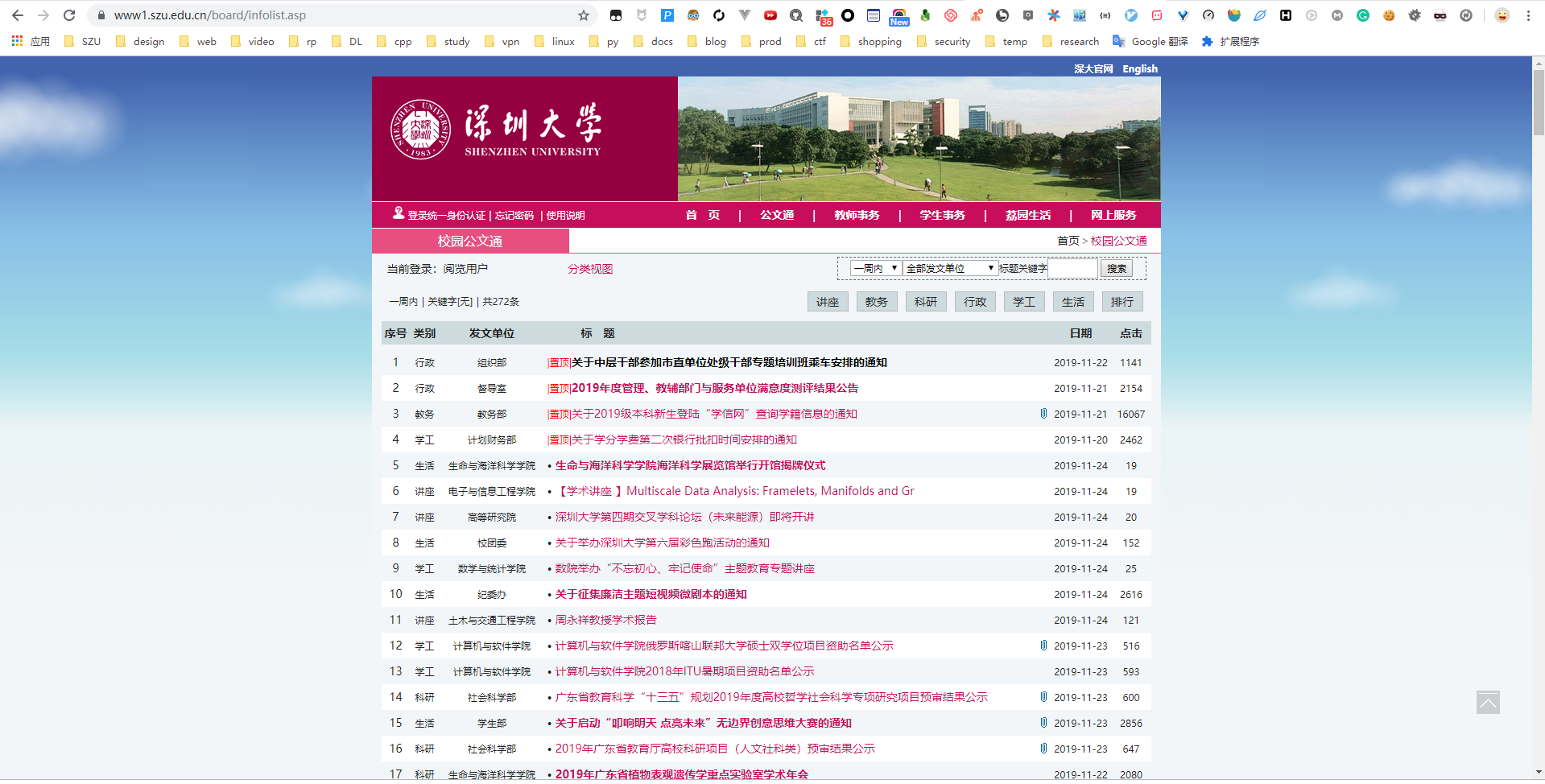
直接贴出函数吧,requests 加 BeautifulSoup 也用过好多回了,轻车熟路,首先获取 http 返回文本,再用 BeautifulSoup 提取元素,放到一个列表中
获取请求文本
def get_response(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
return response.text
得到想要的信息列表
def get_info_list(text):
soup = BeautifulSoup(text, 'html.parser')
soup_category = soup.find_all('a', href=re.compile('\?infotype'), title='')
soup_organization = soup.find_all('a', href='#')
soup_title = soup.find_all('td', align='left')
soup_time = soup.find_all('td', style="font-size: 9pt", align="center")
res = []
list_category = [c.text for c in soup_category]
list_organization = [c.text for c in soup_organization][1:]
list_title = [c.text for c in soup_title]
list_time = [c.text for c in soup_time if '-' in c.text]
for i in range(len(list_category)):
category = list_category[i]
organization = list_organization[i]
title = list_title[i]
time = list_time[i]
data = {
'category': category,
'organization': organization,
'title': title,
'time': time
}
res.append(data)
return res
定时给自己发送邮件
通过上面这两个函数我们就获取到了一个列表,里面的每一个元素都是个字典,字典 key 为 类别,发文单位,标题,时间,然后我们就用 python 的 smtp 模块来发送邮件给自己了,我自己构造了一个 HTML 网页来发送,smtp 不仅仅可以发送纯文本,还可以发送 HTML 页面,二进制数据等等,还是十分有用的。
但是在这之前,确保发送邮件的账号开通了 smtp 服务,具体怎么开通我就不说了,网上一搜就有,我用的是网易163邮箱发送。
构造发送文本
ef get_email_content(data):
send_str = '<p>以下是最新的公文通,请享用~</p>'
for el in data:
send_str += '''
<table style="font-size:8pt">
<tr>
<td>category: </td>
<td>{}</td>
</tr>
<tr>
<td>organization: </td>
<td>{}</td>
</tr>
<td>title: </td>
<td>{}</td>
</tr>
<td>time: </td>
<td>{}</td>
</tr>
</table>
</br>
<hr>
'''.format(el['category'], el['organization'], el['title'], el['time'])
return send_str
发送邮件
def send_email(send_str):
msg = MIMEText(send_str, 'html', 'utf-8')
msg['From'] = _format_addr('公文通小助手 <%s>' % from_addr)
msg['To'] = _format_addr('管理员 <%s>' % to_addr)
msg['Subject'] = Header('快来打开新鲜出炉的公文通叭~', 'utf-8').encode()
server = smtplib.SMTP(smtp_server, 25)
# server.starttls()
server.set_debuglevel(1)
server.login(from_addr, password)
count = 6
while count:
try:
server.sendmail(from_addr, to_addr, msg.as_string())
break
except Exception as e:
logging.error(e)
count -= 1
server.quit()
这里一定要记得写上 msg['To'] ,否则很大概率被当成垃圾邮件,别问我怎么知道的,当成垃圾邮件之后就会直接报错退出程序,这不是我想要的效果,因此我用了错误捕捉机制,给了 6 次发送机会,一般都能发出去
定时功能
def get_current_hour():
return str(datetime.datetime.now())[11: 13]
if __name__ == "__main__":
url = 'https://www1.szu.edu.cn/board/infolist.asp'
while True:
if get_current_hour() == '08' or get_current_hour() == '20':
msg = get_email_content(get_info_list(get_response(url)))
send_email(msg)
logging.info('send successfully!')
time.sleep(3600)
这里的逻辑很好理解,获取当前的时间,如果是早上或者下午 8 点的话就开始爬取并且发送邮件给自己,,如果不是的话就让程度休息一个小时再继续执行 if 语句,因此,每一天我会收到两封邮件,下面看看效果图吧

上传服务器
原先打算部署在自己的 Google-cloud 云服务器上,后来试了一下,要登录学生账号才让访问,又不想挂 VPN 翻回学校,就算了,有内网服务器的话直接就可以挂在上面,只需要执行下面的代码就可以在后台运行这个脚本,即使 ssh 断开连接也没事,我是直接跑在我电脑上了(反正我电脑 24 小时开机)
$ $ nohup python spider.py &
事后
这个程序还有许多可以改进的地方,比如目前只能够发送给一个人,发送多人的话就会大概率被当成垃圾邮件,一直发不出去,而且 BeautifulSoup 解析 HTML 一开始的方向有点偏,导致绕了点弯路,也没有封装成一个 Spider 类,不过总体还行吧,只是个练手项目