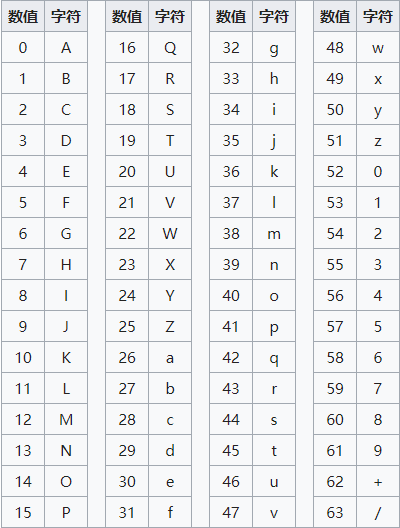
Base64是什么
之前在我的印象中, Base64 很常见,很多地方都会听到这个名词,在 ctf 比赛中更是常见,因此,有必要搞懂它的原理。在维基百科中是这么介绍的,Base64 是一种基于 64 个可打印字符来表示二进制数据的表示方法。由于 2 ^ 6 = 64,所以每 6 个 bit 为一个单元,对应某个可打印字符。3 个字节有 24 个 bit ,对应于 4 个 Base64 单元,即 3 个字节可由 4 个可打印字符来表示
也就是说,用可打印的 ASCII 字符来表示二进制数据,也可能是其他不可打印的 ASCII 码,比如图像中的数据。这 64 个字符是 52 个大小写的字母加上 10 个数字再加上 / 和 + ,有个特殊的 = 用来作为补零时的后缀。
说到这里,就要先来看看这 64 个字符的对应表了,六个 bit 能表示的数为 0-63,和这些字符是一一对应的
Why Base64
我们知道在计算机中的字节共有256个组合,对应就是ascii码,而ascii码的128~255之间的值是不可见字符。而在网络上交换数据时,比如说从A地传到B地,往往要经过多个路由设备,由于不同的设备对字符的处理方式有一些不同,这样那些不可见字符就有可能被处理错误,这是不利于传输的。所以就先把数据先做一个Base64编码,统统变成可见字符,这样出错的可能性就大降低了。
Base64转换
一般涉及到编码转换的地方都会用到 Base64 ,由于是 8bit 转 6bit,所以编码转换之后的数据会比之前长,是原来的 4/3 倍。那么我们来看看他是怎么转换的,这里我们用 Man 作为例子
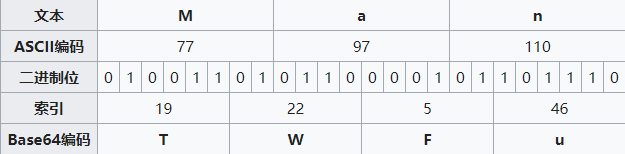
首先就是将字符的 ASCII 码换成二进制,从高位取 6 个 bit ,再转化成十进制, 结合上面的 Base64 对照表,就能够得出对应的字符。
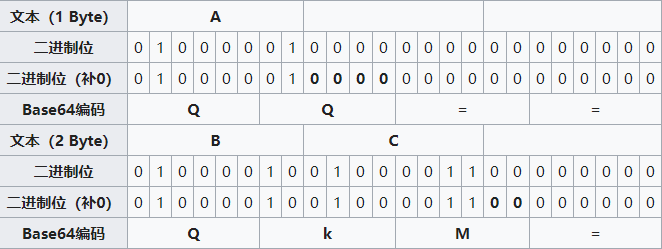
但是如果编码的字节数不能被 3 整除的话,后面就会多出一个或两个字节,这种情况下就用 0 填充缺省的字节,使其能够被 3 整除,再像上面一样进行 Base64 转换,并在编码后的 Base64 文本后加上一个或两个 = ,代表填补的字节数。
也就是说,当最后剩余两个八位(待补足)字节(2个byte)时,最后一个6位的Base64字节块有四位是0值,最后附加上两个等号;如果最后剩余一个八位(待补足)字节(1个byte)时,最后一个6位的base字节块有两位是0值,最后附加一个等号。
Base64 在 URL 中的使用
由于标准 Base64 编码过后的数据会出现 / 和 + ,在 URL 中是由特殊含义的,浏览器会将他们变为形如 %xx 的格式,这些 % 存入数据库时还要进行转换,因此 URL 改进的 Base64 就用 - 和 _ 取代了这两个字符,并且不会在末尾填充 = 号
Base64 隐写
在 ctf 中有次遇到了一道 Base64 隐写题,感觉很巧妙,Base64 隐写就是利用解码时丢掉的数据进行信息隐藏,我们先来看看 Base64 解码是怎么解的,拿上图为例子
看看下面一行的 BC ,编码后变成了 QkM= ,解码的过程就是下面这样:
-
将
=去掉,剩下来的字符对着 Base64 编码表转换成相应的二进制,也就是QkM= -> QkM -> 010000100100001100 -
从左到右,按 8 个 bit 为一组,扔掉多余的位,将剩余的转换成 ASCII 码,也就是
01000010 01000011 00 -> 01000010 01000011 -> 66 67 -> BC
那么隐写就发生在这个时候,我们将上图加粗的零给丢掉了,因为这玩意是解码时候补上去的,所以修改这些零对解码数据没有影响,但是 = 那里的零不能拿来修改,否则 = 的数量就不对了,破坏了解码第一步,加粗的零作为最后一个字符的二进制组成部分,还原时只用到了最后一个字符二进制的前部分,后面的部分不会影响还原。唯一的变化就是最后一个字符会变化!
拿上面的例子讲,一个 = 可以隐写两个 bit ,有四种组合,因此 QkM= ,QkN= ,QkO= ,QkP= 最终都会还原成 BC ,不信可以试试看。而一个 Base64 编码的字符串最多有两个 = ,隐藏的信息有限,所以一般会给很多行文本,每一行隐藏一些,最终将这些信息拼接起来得到隐写信息。
Python Script
这里就把 Base64 隐写编码和解码的脚本贴出来,是用 Python3 写的
编码(有点小问题,留个坑)
import base64
flag = 'flag{base_64_is_funny}'
bin_str = ''.join([bin(ord(c)).replace('0b', '').zfill(8) for c in flag])
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('raw.txt', 'r') as fin, open('encode.txt', 'w+') as fout:
for line in fin.readlines():
row_str = str(base64.b64encode((line.replace('\n', '')).encode('utf-8')), 'utf-8')
equalnum = row_str.count('=')
if equalnum and len(bin_str):
offset = int('0b' + bin_str[: equalnum * 2], 2)
last_char = row_str[len(row_str) - equalnum - 1] # the last character
row_str = row_str.replace(last_char, base64chars[base64chars.index(last_char) + offset]) # change the last character
bin_str = bin_str[equalnum * 2:]
fout.write(row_str + '\n')
解码
import base64
#coding=utf-8
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
#文件路径
with open('encode.txt', 'rb') as f:
flag = ''
bin_str = ''
for line in f.readlines():
stegb64 = str(line, 'utf-8').strip('\n')
rowb64 = str(base64.b64encode(base64.b64decode(stegb64)), 'utf-8').strip('\n')
offset = abs(base64chars.index(stegb64.replace('=', '')[-1]) - base64chars.index(rowb64.replace('=', '')[-1]))
equalnum = stegb64.count('=') # no equalnum no offset
if equalnum:
bin_str += bin(offset)[2:].zfill(equalnum * 2)
res = [chr(int(bin_str[i:i + 8], 2)) for i in range(0, len(bin_str), 8)]
print(res)
reference
https://zh.wikipedia.org/wiki/Base64
https://www.tr0y.wang/2017/06/14/Base64steg/
https://www.zhihu.com/question/36306744/answer/71626823