Nearest Neighbor Classifier
这节课开始介绍第一种分类器: 最邻近分类器(Nearest Neighbor Classifier), 这种分类器与神经网络(Convolutional Neural Network)并没有啥关系, 只是一种最简单的将图片分类的分类器.
他的原理就是:
- 收集训练集的所有样本和标签并且储存
- 将待分类图片与每一张图片进行比较(pixel-wise),选出距离最小的一张图,那么将给待分类图片分成此类
- 没啦
真的是非常简单, 就完全比较像素之间的差异, 设想训练集中有和待分类样本数据一样的图, 那么两者之间的距离就为 0 ,肯定是最近的了, 不过这种方法这么粗暴肯定会有短板, 那就是:
- 每一个训练集都要存储, 占用巨大的存储空间
- 一个待分类样本要与所有训练集进行比较,耗时很大
- 准确度不高
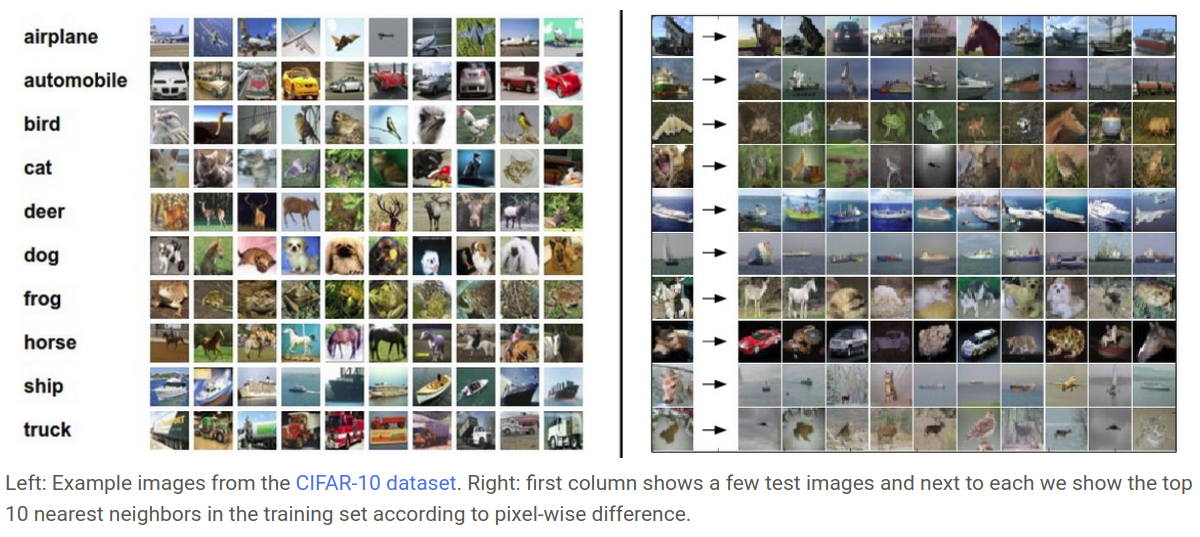
下面给出两幅图,左边是 CIFAR 10 数据集的一些样本,右图第一列是测试样本,后面列出了距离测试样本距离最近的十个类别,看到第八个测试样本,是一匹马,但是最邻近算法却预测出他是辆车,肯定错了。。这种情况可能就是因为他们都有很相似的黑色背景(滑稽)
How to determine distance
下面来介绍一下最邻近算法怎样计算两张图片之间的距离:这里老师说到了 L1 距离和 L2 距离,我上课的时候还记得有汉明距离,马氏距离,欧氏距离等,但是可能不是用于图像分类,因此这里就说下 L1 距离和 L2 距离
L1 距离就是两张图片中对应的每一个像素点的值都相减取绝对值,然后再求和,得出的便为这两张图之间的距离
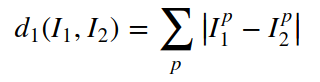
给出一个 L1 距离的例子,方便理解,也就是说,如果图片很相似的话,两张图间的距离会很小,如果差异很大,那么两张图的距离会很大.
L2 距离是两张图片中对应的每一个像素点的值都相减取平方,相加再开根号,得出的便为这两张图之间的距离
那么我们一般使用 L1 距离还是 L2 距离呢?这里给出了,使用 L1 距离的准确率是 38.6% ,使用 L2 距离的准确率为 35.8% ,呵呵哈哈哈或或那我们以后就选 L1 距离吧(误 ,不过这里又说道 L1 和 L2 距离都是在 P 范数中运用最多的(虽然我并不知道 P 范数是啥),这是个超参数,要在实际应用中尝试才知道。
K Nearest Neighbor Classifier
最邻近算法只取了距离最近的一个类,这样很不好,因为可能会受到噪点干扰,因此改进的方案就是 K邻近算法(KNN) ,它选取距离样本最近的 K 个类进行投票。e.g. 测试样本为狗,k = 5 ,距离样本最近的五个类分别是 猫, 蛇, 狗,狗,狗,那么这个样本最终的分类就是狗;如果是 猫,猫,猫,蛇,狗,那么最终分类为猫。
下图给出了直观的解释图,最左边一幅为训练集的分布,右边两幅图的背景表示了测试集的预测情况,可以看到,k = 5 时,样本受噪点影响明显变小了,但是出现了白色的区域,这表示分类模糊的点,因为投票中可能有两个类的票数一样,所以分类器不知道该将其规为哪一类。

How to choose K
实际应用中,如果用到邻近算法,我们都是用 k邻近,但是这个 K 怎么挑选呢?
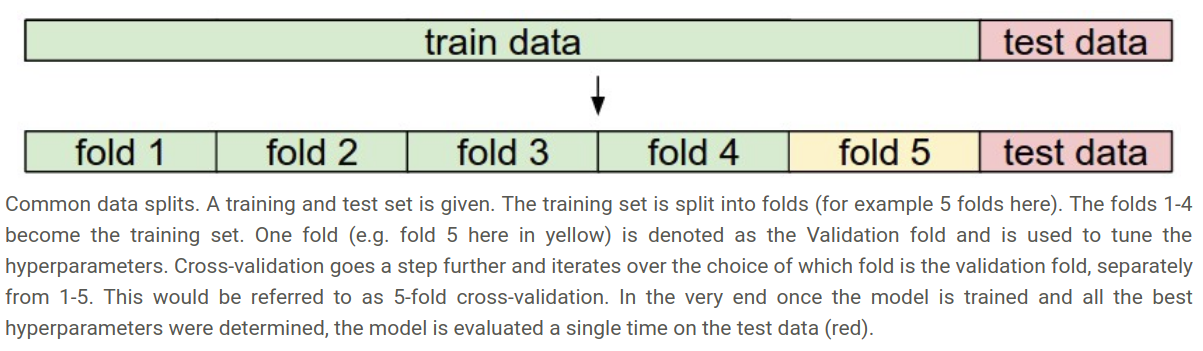
你可能会说直接在验证集中不断地尝试 k 的取值,选出效果最好时候的 k 值,千万不要这么做,任何时候,验证集都应该被当成宝贵的资源,千万不能动用验证集,这是在最后一步验证模型的准确度才能用上的。否则,超参数在你的验证集上跑的特别好,但是换了个验证集就不一定了,这会导致模型过拟合,就像是考试时提前把试卷给你看了,你考了很高的分数,但是换份试卷你就又做不出来了。所以,验证集的作用只是在最后一步测试模型的泛化能力,不能在验证集上做手脚。
然而 k 以及其他超参数可以通过验证集(Validation sets)调优:
一种方法是在训练集中取出一些样本作为验证集,在训练集中训练好模型之后,不断改变 k 的值,在验证集中对 k 进行调优,选出模型表现最好时的 k ,用这个值在测试集中评估模型的准确率。
另一种方法是交叉验证(Cross-validation),这是在我们的训练集样本很少的情况下,就可以通过交叉验证的方法来调优超参数,思路就是:将训练集随机平分成几份,用一份作为验证集,然后其他几份作为训练集,在其他几份训练集上训练模型,然后在这一份验证集中根据效果调优 k 值,再又接下去,用另一份数据作为验证集,这样的话,全部迭代下来,我们会得到 很多个模型,假设将训练集分成了 5 份,则有 4 份作为训练集,一份作为验证集,一次迭代我们可以得到 5 个模型,取这 5 个模型准确率的平均值用于评估该模型,然后变化 k 值,寻找最优的一个 k 值,便可以认为这个 k 值是最优的,最后在测试集上测试性能。

However 人们一般不喜欢用交叉验证,而是更喜欢将训练集分出一部分作为验证集,因为交叉训练所花费的算力很昂贵。而且对于交叉验证,验证集的份数取决于此模型中超参数的多少,超参数越多,则需要越大的验证集,一般来讲,当我们的训练集很少时(甚至只有几百个时)用交叉验证会更安全,一般的做法是将训练集分成3 个 5 个或10 个 fold 来进行交叉验证。
Pros and Cons of Nearest Neighbor classifier
优点:
- 简单易懂
- 训练不用什么时间,因为只是存储了所有训练集的信息
- 目前很多研究在改进邻近法的算法耗时
- 在数据很低维时是个不错的选择
缺点:
- 所需存储空间大,因为要存储所有的训练集
- 虽然训练不用花什么时间,但是时间全花在预测的时候,要让待分类样本与每个训练集做比较
- 对于高维的样本并不太适用,基本不用于分类图像
- 失去了图像的语义信息,光凭像素间的相似度来判断

理想情况下,我们希望所有10个类的图像都能形成它们自己的集群,这样同一个类的图像彼此之间就不会受到无关的特征和变化(如背景)的影响。然而,要获得这个属性,我们必须超越原始像素。
Summary
想在实际中运用 KNN 的话(希望不要在图像分类上应用),主要经过下步骤(有些超纲,还好我学过):
- 准备好数据,将特征归一化为零均值和单位方差
- 如果数据的维度很高,考虑用算法降维,例如 PCA
- 随机将训练集拆分为训练集和验证集,验证集的比例取决于模型的超参数多少,超参数越多的话就需要越大的验证集来评估你的模型。如果运算设备 ok 或者你的训练集太少的话,最好用交叉验证,而且拆分的 fold 越多,效果越好,当然,运算的复杂度也越大。
- 在拥有多种 k 值(越多越好)和不同距离类型(L1和L2是很好的选择)的验证数据(如果进行交叉验证的话则是对于所有 fold 的数据)上对kNN分类器进行训练和评估
- KNN 太慢的话可以考虑用一些库来加速,虽然会降低一些精确度。
- 选择上面评估出来的最好的超参数在测试集上评估模型。